A practical guide to SLMs: main architectures, when they outperform frontier models on production tasks, and how to fine-tune one.

TL;DR: Small language models (SLMs) are neural language models typically defined by their ability to run on a single GPU or CPU, most commonly under 10 billion parameters. They span three main architectures: encoder-only, decoder-only, and encoder-decoder. A fine-tuned SLM will often outperform a frontier model on a specific production task at a fraction of the cost and latency. This guide covers what SLMs are (including the architecture differences most intro articles skip), how they compare to LLMs for different use cases, and a practical walkthrough for fine-tuning one.
Not every production AI problem needs a 70-billion-parameter model. For a large share of real-world tasks (classification, entity extraction, content moderation, summarization over a specific document type), a well-tuned small language model can outperform larger models in accuracy, speed, and cost, all while running on a single CPU.
Consider two examples from our own research. GLiNER2, a 205M-parameter encoder model, sits within 1 F1 point of GPT-4o on CrossNER overall and beats it on the Literature subset, while running entirely on CPU [1]. GLiGuard, at 300M parameters, reaches within 1.7 F1 points of the strongest open safety moderation model evaluated, while running roughly 16x faster in both throughput and latency [2]. These results come from architecture choices, not scale. For well-defined production tasks, the right small model routinely outperforms large generalist models.
This guide covers what SLMs are (including architecture types and parameter thresholds that most introductions skip), how they compare to LLMs for different use cases, and a high-level overview of how to fine-tune one.
What is a small language model?
A small language model is a neural language model defined primarily by its deployability on constrained hardware. Parameter count is the most common proxy, but there is no universal cutoff.
Industry shorthand commonly cites "under 10 billion parameters" as a working threshold, though formal definitions are vaguer: IBM, for instance, describes SLMs as ranging from "a few million to a few billion" parameters [3]. The ambiguity is real: a 7B model in 2025 has capabilities that rival GPT-3.5 from 2022, and what counts as "small" is drifting upward as hardware improves.
The more useful framing: a model is "small" if it can run on a single GPU or CPU without multi-node infrastructure. That is the practical distinction between an SLM and an LLM for most teams. In practice, the term covers models from ~100 million to ~10 billion parameters, with the 1B–7B range being the most common deployment target for fine-tuned SLMs.
Mixture-of-Experts (MoE) architecture adds an exception to the parameter count definition. DeepSeek V4 Flash has 284 billion total parameters, but activates only 13 billion per token during inference [4]. Gemma 4's 26B MoE model activates only 3.8 billion parameters per token [5]. For compute and latency purposes, these behave like 13B and 3.8B models respectively. Whether you call them "small" depends on your available hardware, not the headline parameter count.
The "small" in SLM refers to scale, not capability on a specific task. A 300M parameter encoder fine-tuned on your domain can outperform a 70B generalist model on that task, at a fraction of the latency and cost.
Types of SLMs
SLMs vary along two axes: architecture and modality.
By architecture
The architecture you choose determines what tasks your model can solve and how it processes input. Getting this decision right before selecting a base model will save you significant compute and debugging time downstream.
Encoder-only models
Encoder-only models process the entire input sequence in a single bidirectional forward pass, producing a contextualized representation of every token simultaneously. They do not generate text autoregressively. This makes them well-suited for tasks where the output is a label, a span, or a structured extraction from the input: text classification, named entity recognition, relation extraction, and embedding generation. Because all tokens attend to each other in one pass (rather than generating output token by token), encoder-only models are significantly faster than decoder-only models on classification tasks and can run efficiently on CPU.
Examples: BERT, RoBERTa, GLiNER2, GLiGuard.
The practical case for encoder-only architecture is illustrated clearly in our own work. Most state-of-the-art guardrail models for LLM safety moderation are decoder-based (LlamaGuard, ShieldGemma, Qwen3Guard), ranging from 7B to 27B parameters. They use autoregressive text generation to produce a safety verdict, which is fundamentally a classification problem. Generating output token by token introduces latency that scales with output length and prevents parallel evaluation across multiple safety dimensions [2]. GLiGuard, a 300M encoder, evaluates all four moderation dimensions in a single forward pass and is 16x faster in throughput while matching models 23–90x its size in accuracy [2].
A similar pattern appears in PII detection. OpenAI's Privacy Filter is a 1.5B-parameter sparse MoE (50M active per token) derived from gpt-oss and repurposed as a token classifier. The architecture locks developers into a fixed schema of 8 entity types and cannot be customized at inference time. GLiNER2-PII, a 300M native encoder, evaluates 42 entity types simultaneously in one forward pass with a schema provided at inference time, and achieves the highest span-level F1 on the SPY benchmark — outperforming OpenAI's Privacy Filter, NVIDIA's GLiNER-PII, and other publicly available detectors [11].
The principle: if your output is a label, a span, or a structured extraction, use an encoder. Using a decoder for this task means using text generation to solve a classification problem, which wastes both compute and latency.
Decoder-only models
Decoder-only models generate text token by token, with each token predicted from all preceding tokens (causal attention). This architecture is the right choice for any task where the output is free-form text: instruction following, chat, code generation, summarization, and translation. Most modern SLMs intended for fine-tuning on generative tasks are decoder-only. Examples: Llama, Qwen3, Gemma 4, Phi-4, DeepSeek.
Encoder-decoder models
Encoder-decoder models use an encoder to process the input and a decoder to generate the output. This is the original sequence-to-sequence (seq2seq) architecture. It remains a strong choice for tasks where both input and output are structured text: translation, abstractive summarization, and structured question answering. Examples: T5, BART, Flan-T5. Less commonly used as a fine-tuning base today compared to the 2022–2024 era, but still competitive for specific seq2seq tasks. Google's T5Gemma, released in 2025, revisits this architecture and shows that encoder-decoder models can achieve higher accuracy than decoder-only models of the same size on a range of tasks [6].
Summary for task selection:
Task type | Best architecture | Why |
|---|---|---|
Text classification, NER, extraction | Encoder-only | Single forward pass, deterministic, CPU-friendly |
Safety moderation, guardrails | Encoder-only | Multi-task evaluation in one pass, low latency |
PII detection and redaction | Encoder-only | Span-level output, label-conditioned |
Instruction following, chat, code | Decoder-only | Generative output required |
Translation, abstractive summarization | Encoder-decoder | Structured input and output |
Embeddings and semantic search | Encoder-only | Rich token-level representations |
By modality
Most SLMs are text-only. Multimodal small language models add vision capability, processing image and text together.
The leading multimodal SLMs as of May 2026 include:
Gemma 4 (Google, Apache 2.0): The Gemma 4 family is natively multimodal, processing image and text in a single model. Dense variants include E2B (~2B), E4B (~4B), and 31B; the 26B MoE model activates only 3.8B parameters per inference pass, making it practical on a single GPU. A strong general-purpose choice if you need Google-quality vision-language capability without paying frontier API prices.
Qwen2.5-VL (3B and 7B variants): Strong document and chart understanding, multilingual vision support, and a 125K token context window. Qwen2.5-VL 7B outperforms the larger 11B Llama 3.2 Vision across several major benchmarks [^7]. The long context window makes it practical for processing lengthy documents with embedded images, multi-image sequences, and agentic pipelines that need to reason over visual content.
Phi-4 Multimodal (3.8B, Microsoft): Designed for mobile and edge deployment. Practical for mobile AI assistants, augmented reality interfaces, and offline kiosks that need to process both text and images without a cloud API.
Moondream2 (~2B): Purpose-built for edge-constrained hardware. Limited context window (~2,000 tokens) but extremely compact. A reasonable choice for devices with minimal VRAM where a Qwen2.5-VL would not fit.
PaliGemma 2 (Google): General-purpose vision-language tasks, particularly strong on document understanding and scientific figure interpretation.
For pure text tasks, text-only SLMs are faster, cheaper to run, and significantly simpler to fine-tune. Multimodal models add image processing overhead even when images are not present in a request. Only add multimodal capability if your use case genuinely requires it.
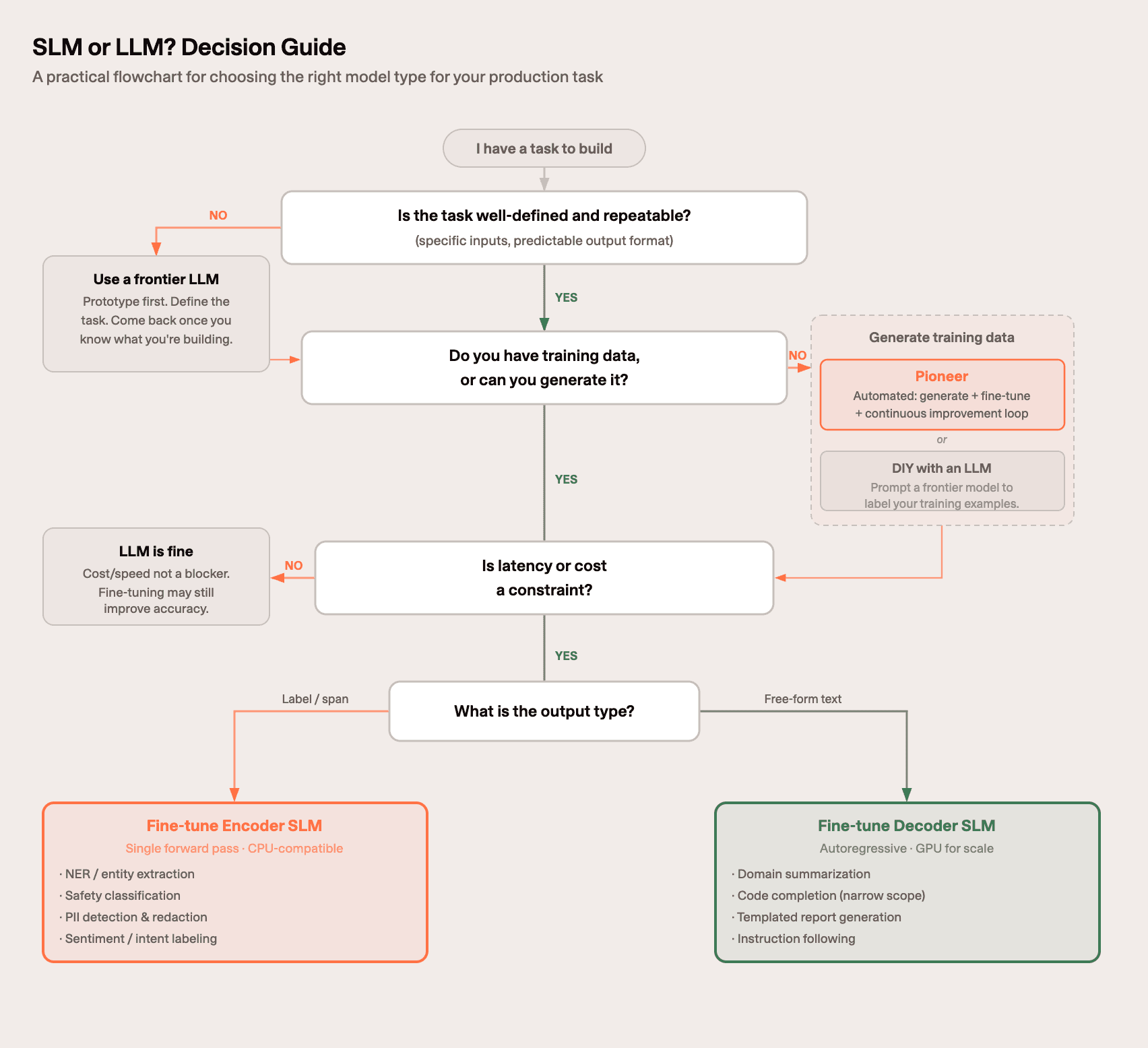
SLMs vs. LLMs: when to use what
There is no universal winner. The right choice depends on your task scope, latency requirements, data situation, and infrastructure constraints.
Factor | SLM | LLM |
|---|---|---|
Task scope | Narrow, well-defined | Broad, open-ended |
Latency | Milliseconds | Hundreds of ms to seconds |
Inference cost | Up to 10x cheaper | High |
Fine-tuning required | Usually yes | Often optional |
Hardware | Single GPU or CPU | Multi-GPU or managed API |
Training data required | Labeled or synthetic examples | Can work zero-shot |
Accuracy on specialized tasks | Higher when fine-tuned | Lower without fine-tuning |
Complex multi-step reasoning | Limited | Strong |
Data privacy | Model can run on-prem | Data sent to third-party |
Use cases where SLMs consistently win
Email and ticket triage: Classifying incoming support tickets, sales emails, or alerts into defined categories (billing, technical, feature request, etc.) is a high-volume, well-defined task. A fine-tuned 7B decoder or 200M encoder model running on a single CPU handles thousands of requests per second at negligible cost. A paper from ServiceNow Research found that fine-tuned SLMs outperform LLM prompting on low-code workflow generation tasks of comparable structure [8].
PII detection and redaction in data pipelines: Before routing documents through an analytics pipeline, model training run, or AI agent, you need to strip sensitive information. This is a classification/extraction task over a fixed schema. Encoder models like GLiNER2-PII handle 42 PII entity types in a single forward pass, with deterministic outputs and no sampling variance [1]. A decoder model prompted to do the same task is slower, less deterministic, and significantly more expensive per document.
Safety guardrails in LLM applications: Any LLM deployed to end users needs a moderation layer that intercepts harmful, off-topic, or policy-violating inputs before they reach the model, and flags outputs before they reach the user. This layer runs on every single request, so its latency and throughput directly affect the cost and responsiveness of your entire system. A guardrail model needs to be fast and accurate on a fixed taxonomy of violation categories (prompt injection, jailbreak attempts, hate speech, self-harm, and similar), not general-purpose. It does not need to be large. GLiGuard at 300M parameters handles all moderation dimensions in one pass at 16x the throughput of the best 7B–27B decoder-based alternatives [2].
Named entity extraction in compliance workflows: Legal, healthcare, and financial documents arrive as unstructured prose but must feed deterministic rule checks (sanctions screening, threshold triggers, audit trails) that require discrete, structured facts. Extracting entities (names, dates, transaction IDs, medical codes) is the bridge between the two. Encoder models are the right tool for this: they produce exact character spans, run without GPU, and can be fine-tuned on domain-specific schemas without large compute budgets.
RAG query classification and routing: In retrieval-augmented generation systems, a small classifier that determines which index or tool to route a query to can be a fine-tuned encoder with <1ms latency. Using a frontier model for this routing step is relatively common and an unnecessary cost driver.
Use cases where LLMs still win
Open-ended reasoning and complex multi-step tasks: Tasks where the input is unpredictable or requires synthesizing broad world knowledge (research summaries, legal analysis across novel case law, complex code architecture review) still benefit from frontier model scale.
Prototyping before task definition: If you haven't yet defined the task precisely, an LLM lets you iterate without committing to a training set. Once the task is defined, replace the LLM with a fine-tuned SLM for production.
Tasks with no training data and no path to generating it: Zero-shot LLM prompting remains the only practical option when you genuinely cannot create labeled examples.
The common production pattern
Start with an LLM for prototyping. Define the task through iteration. Use the LLM to generate synthetic training data. Fine-tune a small model on that data. Deploy the small model for production inference. Keep the LLM as a fallback for edge cases the SLM cannot handle.
The LLM generates the training signal; the SLM provides the production efficiency.
Key advantages of SLMs
Accuracy on specialized tasks
This is the most frequently underestimated advantage. A fine-tuned SLM does not need to spread its capacity across millions of topics. All of its representational capacity is focused on your task. GLiGuard (300M parameters) falls within 1.7 F1 points of the strongest safety moderation model available while being 23–90x smaller [2]. GLiNER2 (205M parameters) sits within 1 F1 point of GPT-4o on CrossNER overall and beats it on the Literature subset [1]. These are not cherry-picked results. For token-level classification and extraction tasks specifically, fine-tuned encoder models routinely match or exceed models many times their size [9].
Latency
Decoder-only SLMs in the 7B range generate tokens in roughly 20–50ms per token on modern GPU hardware. Encoder-only models like GLiNER2 process an entire input sequence in a single forward pass on CPU [1]. Frontier models typically introduce 500ms to 2s of latency, which makes them impractical for user-facing features or high-throughput pipelines where response time is part of the product experience.
Cost
Inference with a frontier model typically costs $15–30 per million output tokens (Claude Opus 4.7 and GPT-5.5 sit at the upper end). A self-hosted or fine-tuned SLM running on dedicated hardware can reduce that cost by a factor of 5–10x. For applications processing the same system prompt millions of times per day (email classification, content moderation, document extraction), this compounds significantly. Teams switching repetitive frontier model calls to fine-tuned SLMs commonly report cost reductions in this range.
Deployment and data privacy
SLMs can run on a single GPU, a CPU server, or edge devices. You do not need multi-GPU clusters or a managed cloud API. This means on-prem inference, no third-party data exposure, full model weight ownership, and no vendor lock-in. For regulated industries (healthcare, finance, legal) handling sensitive data, on-prem deployment is often a regulatory requirement, not a preference.
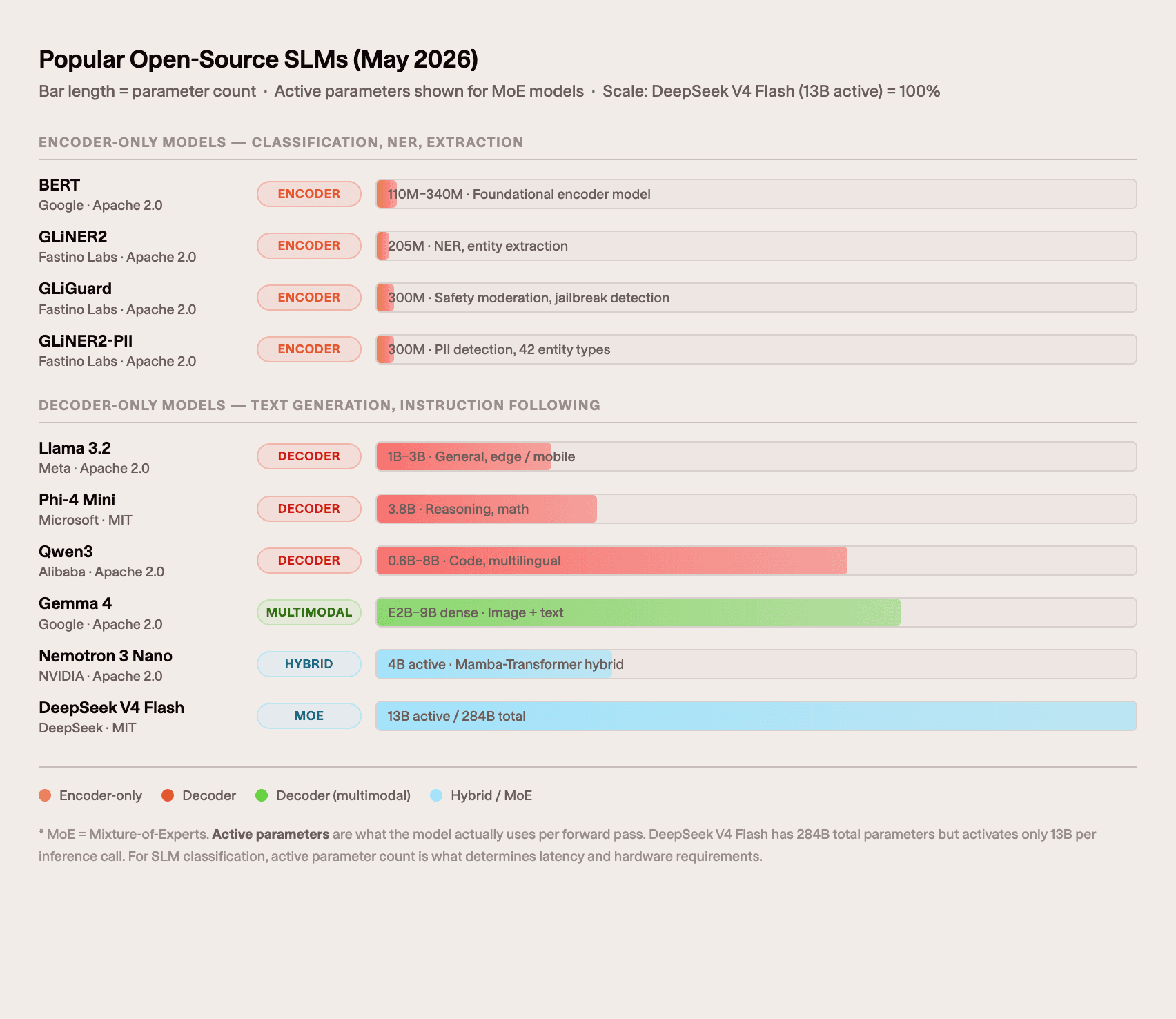
Popular open-source SLMs in 2026
The following models represent the active landscape as of May 2026. The ecosystem has moved quickly: most of these did not exist a year ago.
Decoder models (for generative tasks and instruction following)
Model | Active params | Architecture | License | Strengths |
|---|---|---|---|---|
Qwen3 0.6B–8B | 0.6B–8B (dense) | Decoder | Apache 2.0 | Strong multilingual and coding; hybrid thinking mode |
Gemma 4 E2B / E4B | 2B / 4B | Decoder (dense) | Apache 2.0 | Google's most capable small dense models; strong reasoning benchmarks [5] |
Gemma 4 26B MoE | 3.8B active / 26B total | Decoder (MoE) | Apache 2.0 | 97% of the dense 31B quality at ~3.8B compute cost; practical for single-GPU deployment [5] |
Phi-4 Mini | 3.8B | Decoder | MIT | Microsoft; performs well on math and reasoning relative to parameter count |
NVIDIA Nemotron 3 Nano 4B | 4B | Hybrid (Mamba-Transformer) | NVIDIA open model | Hybrid Mamba-Transformer architecture; 262K context window; designed for edge (fits in 8GB Jetson); 95.4% on MATH500 in reasoning mode [10] |
DeepSeek V4 Flash | 13B active / 284B total | Decoder (MoE) | MIT | Cost-efficient frontier-quality inference; 1M token context; used as API replacement where compute budget is limited [4] |
Llama 3.2 1B / 3B | 1B / 3B | Decoder | Llama license | Meta; widely used fine-tuning base; large community ecosystem |
A note on MoE models in this list: Gemma 4 26B MoE and DeepSeek V4 Flash have large total parameter counts but small active-parameter footprints. From a compute and latency perspective, they behave like 3.8B and 13B models respectively. Whether they qualify as "SLMs" depends on your hardware, not the headline number.
Encoder models (for classification, extraction, and guardrails)
Model | Parameters | Architecture | License | Strengths |
|---|---|---|---|---|
GLiNER2 | 205M | Encoder | Apache 2.0 | Zero-shot and fine-tuned NER, classification, relation extraction; CPU-native; competitive with GPT-4o on CrossNER [1] |
GLiGuard | 300M | Encoder | Apache 2.0 | Multi-task LLM safety moderation in a single forward pass; 16x faster than 7B–27B decoder guardrails [2] |
GLiNER2-PII | 300M | Encoder | Apache 2.0 | 42-entity PII detection and redaction; highest F1 on SPY benchmark; label-conditioned [11] |
Three encoder models are developed by Fastino Labs and available on Hugging Face. For classification and extraction use cases, they are worth evaluating before committing to a decoder-based fine-tuning project.
Multimodal SLMs
Model | Parameters | Strengths |
|---|---|---|
Qwen2.5-VL | 3B, 7B | Document and chart understanding, 125K context, multilingual [7] |
Phi-4 Multimodal | 3.8B | Mobile and edge, offline deployment |
Moondream2 | ~2B | Minimal VRAM, edge-constrained hardware |
PaliGemma 2 | 3B, 10B | Scientific figures, document understanding |
How to fine-tune an SLM
This section is a high-level overview. We'll be covering fine-tuning in much more depth in a dedicated follow-up post.
Fine-tuning adapts a pre-trained base model to your specific task using your data. Here is a practical walkthrough.
Step 1: Define the task precisely
This is the most important step and the most frequently skipped. "Make the model better at customer support" is not a task definition. "Classify incoming support emails into one of six categories (Billing, Technical, Feature Request, Cancellation, Compliment, Other) and extract the primary complaint as a one-sentence summary" is a task definition.
Precision determines everything downstream: how much data you need, which architecture to choose, what your eval metric is, and what success looks like. The narrower the task, the less data you need and the higher your accuracy ceiling. Choose your architecture based on your output type before selecting a specific base model (see the architecture summary table above).
Step 2: Choose a base model
For classification or extraction tasks where output is a label or span: start with an encoder-only model. For encoder-based extraction, GLiNER2 supports a wide range of zero-shot extraction tasks before any fine-tuning, which makes it a useful starting point even before you have training data.
For generative tasks where output is free-form text: choose a decoder-only model. Qwen3 4B or 8B under Apache 2.0 is a solid default for general instruction following. Phi-4 Mini is worth evaluating for math or reasoning-heavy tasks.
For sequence-to-sequence tasks (translation, structured summarization): consider an encoder-decoder model like T5 or Flan-T5 before defaulting to a decoder-only approach.
Step 3: Prepare training data
You need labeled examples: input/output pairs that demonstrate the task correctly. Rough guidelines by task type:
Simple classification (2–6 classes): 200–500 examples per class
Named entity recognition: 500–2,000 annotated sentences
Instruction-following (decoder): 1,000–10,000 examples
If you do not have labeled data, you have two practical options: label manually (accurate but slow) or generate synthetic training data with a frontier model (fast and increasingly standard). Synthetic data generation works well when you can specify the output format precisely. For tasks like classification and extraction, LLM-generated synthetic data routinely produces strong fine-tuning results. This is the same approach used to train GLiNER2-PII: 4,910 synthetic annotated examples generated by GPT-5.4 within Pioneer's constraint-driven framework, covering seven languages and multiple document formats [11].
Quality matters more than volume. Two hundred clean, accurate examples will outperform 2,000 noisy ones.
Step 4: Fine-tune the model
Key parameters:
Learning rate: 1e-5 to 5e-5 for full fine-tuning; 1e-4 to 3e-4 for LoRA/PEFT adapters
Batch size: As large as your GPU VRAM allows, typically 8–32
Epochs: 2–5 for most tasks; more risks overfitting on small datasets
Training method: Full fine-tuning for best results; LoRA (Low-Rank Adaptation) when VRAM is limited
For encoder models (200–500M parameters), full fine-tuning fits on a single A10G (24GB VRAM). For decoder models in the 7B range, LoRA makes fine-tuning feasible on the same hardware. For 4B models, full fine-tuning is typically achievable on a 40GB A100.
Standard tooling: Hugging Face Transformers, Unsloth (fast LoRA fine-tuning), and LLaMA-Factory cover most decoder use cases. For teams that want zero MLOps overhead, Pioneer handles the full pipeline for both encoder and decoder SLMs: synthetic training data generation, LoRA fine-tuning, evaluation, and deployment behind an OpenAI- or Anthropic-compatible endpoint. After deployment, Pioneer's Adaptive Inference mines production failures for high-signal examples, retrains the specialist model automatically, and promotes improved checkpoints behind the same endpoint with no redeployment.
Step 5: Evaluate
Evaluate on a held-out test set your model has never seen. Use task-specific metrics:
Classification: F1 score, precision, and recall per class. Aggregate F1 hides per-class failure modes.
NER / extraction: Span-level F1 (exact match on character spans, not just token overlap)
Generation: ROUGE or BLEU for structured outputs; human eval for open-ended tasks
Compare directly against your baseline (typically the LLM you're replacing) on the same eval set and inputs.
Step 6: Deploy and monitor
For 7B decoder models: one NVIDIA A10G or L4 GPU is sufficient. For encoder models: a single CPU-only machine, no GPU required. For serving, vLLM and SGLang are the standard choices for decoder models. For GLiNER-family encoders, the GLiNER2 library handles inference directly; other encoder models typically go through Hugging Face Transformers, ONNX Runtime, or NVIDIA Triton.
Do not treat deployment as the final step. Production data includes cases your training set did not cover. Log all inputs and outputs, track failure modes, and plan for a retraining cycle.
A key finding from our own production work: naive retraining on production failures without careful curation can degrade model performance. In internal tests, naive retraining approaches degraded performance by up to 43 percentage points, while a curated failure-driven retraining approach improved or preserved performance in every scenario tested. The quality of your failure curation matters as much as collecting the failures in the first place.
This loop is what Pioneer's Adaptive Inference automates: it mines production failures for high-signal examples, retrains a specialist model on them, and benchmarks each run before promoting the new checkpoint behind the same endpoint. The 43-point gap above comes from Pioneer's internal tests against naive retraining baselines.
Conclusion
In many use cases, SLMs are not a replacement for LLMs. For production tasks that are well-defined and repeatable, a fine-tuned SLM will consistently outperform a frontier model on accuracy, cost, and latency. The practical prerequisite is task clarity and training data, both of which are significantly more accessible than they were two years ago.
The architecture decision matters as much as the parameter count. If your output is a label or a span, start with an encoder model. If your output is text, start with a decoder model. Choosing the wrong architecture means building on a foundation optimized for a different problem.
The common production path: prototype with an LLM, define the task, generate synthetic training data with the LLM, fine-tune a small model, deploy with a monitoring loop. The LLM becomes the teacher; the SLM becomes the production model.
For adaptive inference (where the model continuously improves from production logs without manual retraining cycles), Pioneer is Fastino's platform for fine-tuning and deploying open-source SLMs. The GLiNER2, GLiNER2-PII, and GLiGuard models are available open-source on Hugging Face under Apache 2.0.
Frequently asked questions
What parameter size counts as a small language model?
There is no universal consensus. Industry shorthand commonly uses "under 10 billion parameters" as a working threshold, though formal definitions are vaguer (IBM, for instance, describes SLMs as ranging from "a few million to a few billion" parameters) [3]. MoE architecture makes this messier: DeepSeek V4 Flash has 284B total parameters but only 13B active per token, which is the number that determines compute and latency. A more practical definition: a model is "small" if it can run on a single GPU or CPU without multi-node infrastructure.
Can an SLM outperform GPT-4 on my task?
On a specific, well-defined task with adequate fine-tuning, yes. As an example, GLiNER2 (205M parameters) is competitive with GPT-4o on CrossNER (within 1 F1 point overall) and runs entirely on CPU [1]. GLiGuard (300M parameters) matches models 23–90x its size on safety moderation [2]. The qualifier is task specificity.
Why would I use an encoder model instead of a decoder model?
If your task output is a label, a category, or a structured span (classification, NER, PII detection, safety moderation), encoder models are faster, cheaper, and often more accurate than decoder models of any size. Decoder models solve classification problems through text generation, which adds unnecessary latency and non-determinism. Encoder models process the entire input in one forward pass and return a deterministic output. The latency difference is significant: encoder models can process thousands of requests per second on a CPU, while decoder models require a GPU and generate outputs sequentially [2][1].
How much training data do I need to fine-tune an SLM?
For simple classification tasks, 200–500 labeled examples per class is a practical starting point. For NER, 500–2,000 annotated examples. For instruction-following with decoder models, 1,000–10,000 examples. Synthetic data generation (using an LLM to produce labeled examples) significantly reduces this requirement for well-defined tasks and is now a standard part of fine-tuning workflows.
References
[1]: Zaratiana et al. (2025). GLiNER2: An Efficient Multi-Task Information Extraction System with Schema-Driven Interface. Fastino Labs. arXiv:2507.18546. https://arxiv.org/abs/2507.18546 | Blog
[2]: Zaratiana, Newhauser, Hurn-Maloney, Lewis (May 2026). GLiGuard: Schema-Conditioned Classification for LLM Safeguard. Fastino Labs. arXiv:2605.07982. https://arxiv.org/abs/2605.07982 | Blog
[3]: IBM. What are Small Language Models (SLM)? https://www.ibm.com/think/topics/small-language-models
[4]: DeepSeek. DeepSeek V4 Preview Release. April 2026. https://api-docs.deepseek.com/news/news260424
[5]: Manik and Wang (April 2026). Gemma 4, Phi-4, and Qwen3: Accuracy-Efficiency Tradeoffs in Dense and MoE Reasoning Language Models. arXiv:2604.07035. https://arxiv.org/abs/2604.07035
[6]: Google Developers Blog. T5Gemma: A new collection of encoder-decoder Gemma models. https://developers.googleblog.com/en/t5gemma/
[7]: Qwen Team (2025). Qwen2.5-VL Technical Report. arXiv:2502.13923. https://arxiv.org/abs/2502.13923
[8]: Marquez et al. (2025). Fine-Tune an SLM or Prompt an LLM? The Case of Generating Low-Code Workflows. ServiceNow Research. arXiv:2505.24189. https://arxiv.org/abs/2505.24189
[9]: Valdes Gonzalez (February 2026). Cost-Aware Model Selection for Text Classification: Multi-Objective Trade-offs Between Fine-Tuned Encoders and LLM Prompting in Production. arXiv:2602.06370. https://arxiv.org/abs/2602.06370
[10]: NVIDIA (March 2026). Nemotron 3 Nano 4B: A Compact Hybrid Model for Efficient Local AI. Hugging Face. https://huggingface.co/blog/nvidia/nemotron-3-nano-4b
[11]: Zaratiana, Newhauser, Hurn-Maloney, Lewis (May 2026). GLiNER2-PII: A Multilingual Model for Personally Identifiable Information Extraction. Fastino Labs. arXiv:2605.09973. https://arxiv.org/abs/2605.09973 | Blog