GLiGuard: 16x Faster Safety Moderation with a Small Language Model
By: Mary Newhauser & Urchade Zaratiana
Introducing GLiGuard, a new open source small language model for safety moderation.

As large language models are increasingly deployed in user-facing applications, guardrails are necessary to prevent harmful outputs and protect against misuse. Now that agents can browse the web, execute code, and take real-world actions on a user's behalf, the stakes are considerably higher.
Effective guardrail models act as a safety layer between the user and the model, preventing nefarious user requests from reaching the model and harmful responses from reaching the user. Current guardrail models are effective at safety moderation, but they are built on large generative models with billions of parameters. They use text generation to solve what is fundamentally a classification problem, which makes them slow and costly to run at production scale.
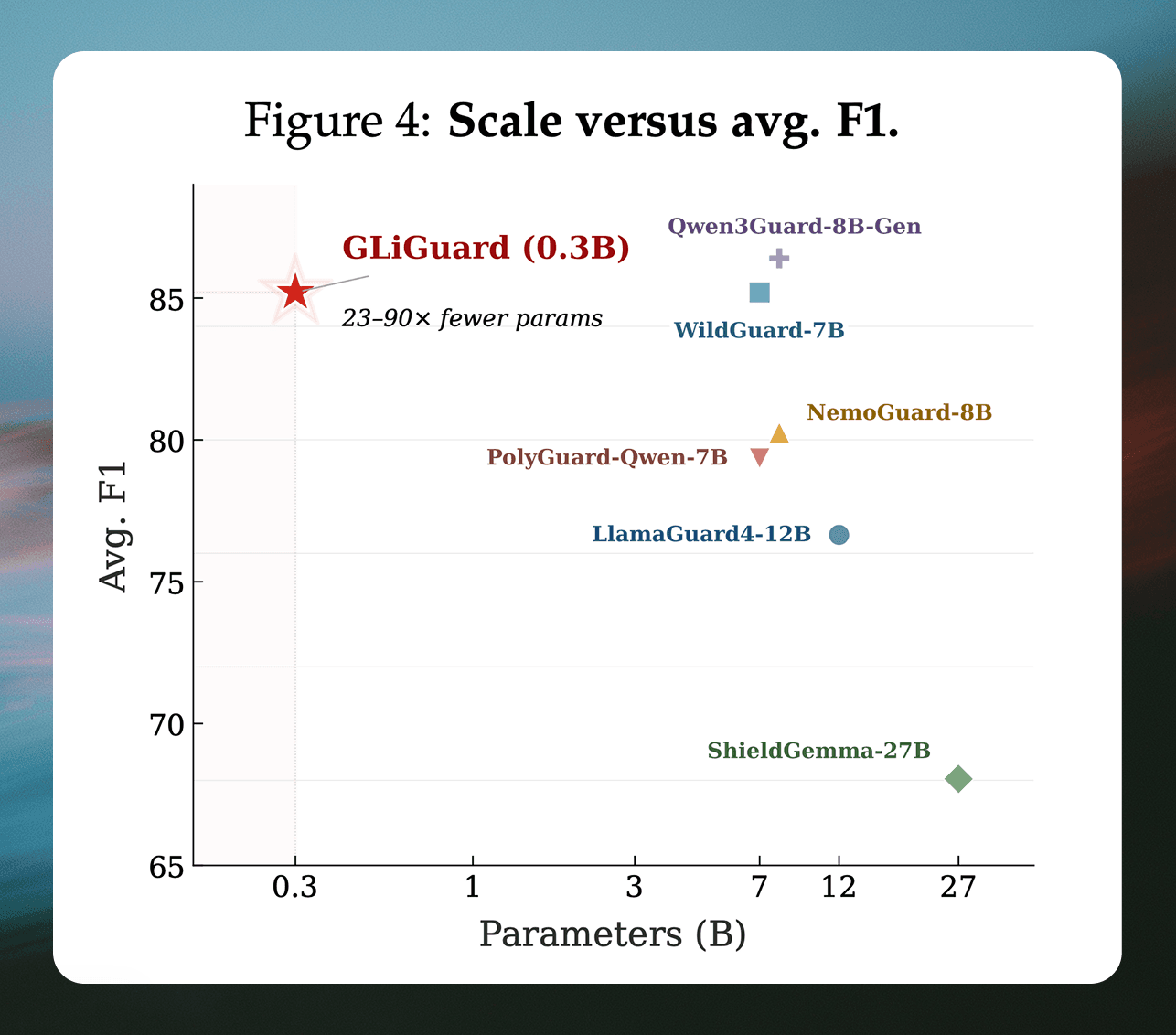
In this post we introduce GLiGuard, a 300 million parameter model designed for content moderation and safety classification, evaluating multiple safety dimensions in a single forward pass. Across nine safety benchmarks, GLiGuard’s accuracy matches or exceeds models that are 23 to 90 times its size while running up to 16 times faster.
GLiGuard model weights are available under the Apache 2.0 license on the Hugging Face Hub and the model is available for inference on Pioneer.
Drawbacks of using decoder LLMs for safety moderation
Most major guardrail models are built on decoder-only transformer architectures, meaning they generate their safety verdicts autoregressively, one token at a time, the same way a large language model generates a response to a chat message. This makes them flexible: they can interpret natural language task descriptions and adapt to new safety policies or harm categories without architectural changes.
However, this flexibility comes at a cost. Autoregressive generation is inherently sequential, which makes it slow and computationally expensive. Current open source state-of-the-art guardrail models range from roughly 7 billion to 27 billion parameters, making them expensive to run and difficult to deploy at the latencies that real-time safety moderation demands.
Compounding the problem, most guardrail models need to assess inputs across multiple safety dimensions: what type of harm is present, whether the user prompt is attempting to bypass safety training, whether the model's response is itself unsafe, and so on.Because decoder models generate output sequentially, these assessments are typically produced one after another, and latency compounds as more criteria are evaluated.
GLiGuard performs four safety moderation tasks in a single pass
GLiGuard is a small encoder-based model that reframes safety moderation as a text classification problem rather than a text generation problem. Encoder models process the entire input at once and output a single classification label for a set of fixed labels, whereas decoder models generate their output one token at a time, left to right.
Instead of generating tokens, GLiGuard encodes both the input text and task definitions (labels) together. These are then fed to the model, which scores every label simultaneously in a single forward pass and returns the highest-scoring label for each task. Because all tasks and their candidate labels are part of the input itself, evaluating additional safety dimensions doesn't add latency; it simply means including more labels in the input.

GLiGuard can be used to filter both user queries and model responses for harmful content and handles four moderation tasks concurrently, all evaluated together in one forward pass:
Safety classification (safe / unsafe). Is the text safe or not? Applied to both user prompts before generation and model responses after generation.
Jailbreak strategy detection (11 strategies). Is the prompt trying to bypass the model's safety training, and if so, how? Strategies include prompt injection, roleplay bypass, instruction override, social engineering, and others. If any jailbreak strategy is detected, the prompt is automatically flagged as unsafe.
Harm category detection (14 categories). What type of harm is present? Categories include violence, sexual content, hate speech, PII exposure, misinformation, child safety, copyright violation, and others. A single input can trigger multiple categories at once.
Refusal detection (compliance / refusal). Did the model refuse the user's request or comply with it? This is tracked separately because it helps measure over-refusal (when a model refuses safe requests) and detect false compliance (when a model appears to comply but doesn't). If a refusal is detected, the response is automatically marked as safe.
GLiGuard evaluates all four of these tasks in a single forward pass, while decoder-based guard models generate each assessment sequentially. This architectural difference has direct implications for both speed and cost, which we'll cover in the next section alongside GLiGuard's benchmark performance against other guardrail models.
How we trained GLiGuard
Training data
We trained GLiGuard on a mixture of human annotated and synthetically generated training data. For prompt safety, response safety, and refusal detection, we used WildGuardTrain, a dataset of 87,000 human-annotated examples.
For harm category and jailbreak strategy detection, we generated labels for the unsafe samples using GPT-4.1. During early training, the model struggled to distinguish between similar harm categories like toxic speech and violence, so we used Pioneer to generate supplemental synthetic data with edge cases targeting these fine-grained distinctions. Full training details are available in our paper.
Fine-tuning method
GLiGuard was trained by fully fine-tuning the GLiNER2-base-v1 checkpoint for 20 epochs using the AdamW optimizer, making it one of the more precise small language models available for content moderation tasks. Full hyperparameter details are available in the paper.
How we evaluated GLiGuard
We evaluated GLiGuard on two dimensions: accuracy and speed. For accuracy, we evaluated GLiGuard across nine established safety benchmarks that cover both prompt and response classification. These benchmarks collectively test whether a model can identify harmful content, withstand adversarial attacks, distinguish between different types of harm, and avoid over-flagging safe content.
We compared GLiGuard against six decoder-based guard models that represent the current state of the art: LlamaGuard4 (12B), WildGuard (7B), ShieldGemma (27B), NemoGuard (8B), PolyGuard (7B), and Qwen3Guard (8B). All results use macro-averaged F1, a standard metric that balances precision and recall, where higher is better and 100 indicates a perfect score.
We also benchmarked latency and throughput on a single NVIDIA A100 GPU against three decoder-based guard models: Qwen3Guard-4B, Qwen3Guard-8B, and ShieldGemma-27B. This measured how many samples each model could process per second and how long a single request takes across a range of batch sizes and sequence lengths.
Accuracy comparable to models 23-90x larger
Across all nine benchmarks, GLiGuard's accuracy matches that of significantly larger decoder models.
GLiGuard scores 87.7 average F1 on prompt classification, within 1.7 points of the best model (PolyGuard-Qwen at 89.4)
Second-highest average F1 on response classification (82.7), behind only Qwen3Guard-8B (84.1)
Outperforms LlamaGuard4-12B, ShieldGemma-27B, and NemoGuard-8B despite being 23-90× smaller
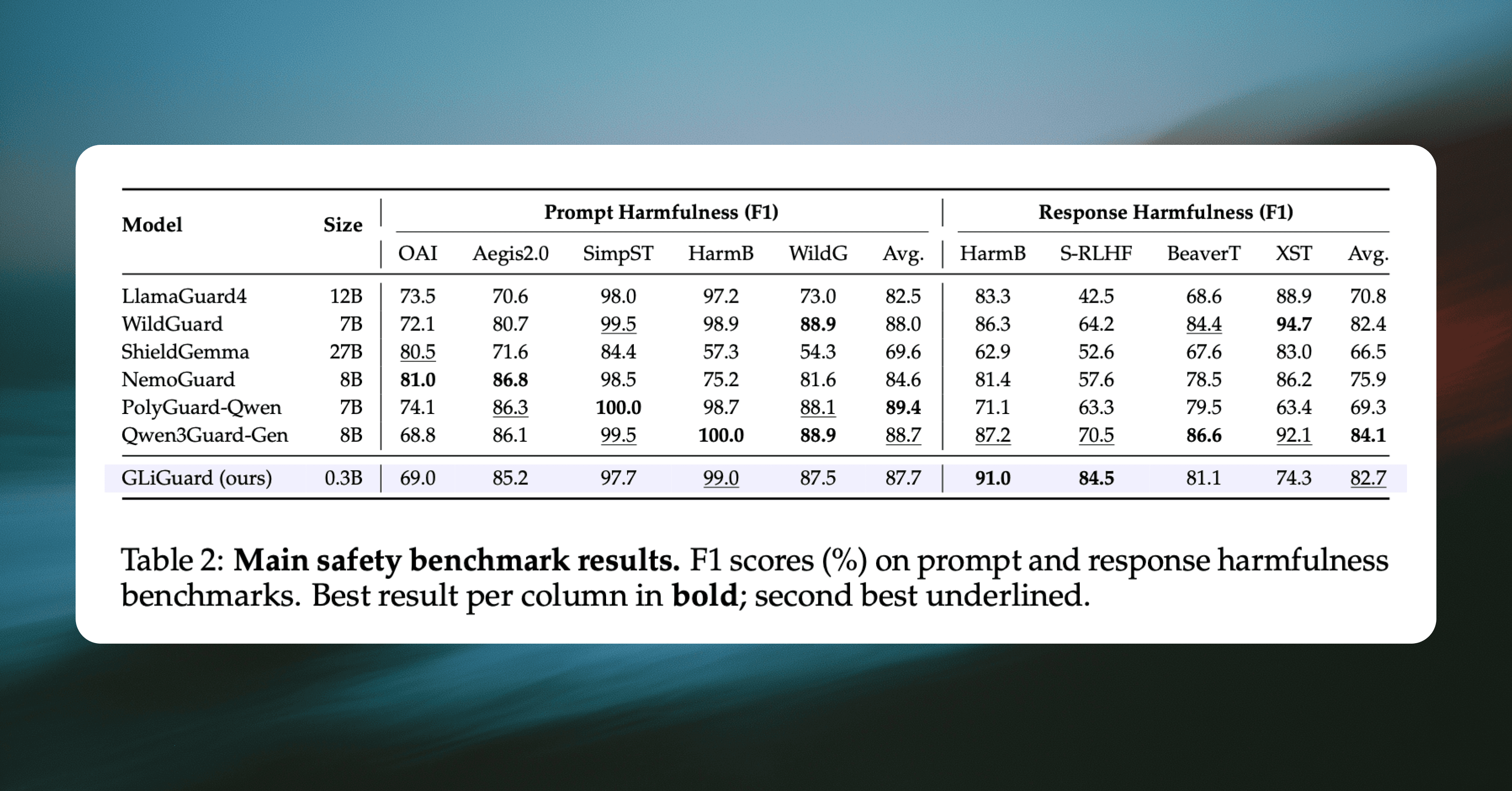
These results show that the accuracy gap between small encoder models and large decoder-based guard models is much narrower than their difference in parameter count would imply. For teams evaluating the best models for harmful content detection and safety moderation, GLiGuard demonstrates that strong classification accuracy for safety tasks can be achieved in a far more compact architecture, without relying on large decoder-based models.
Up to 16x faster than current SOTA models
To measure GLiGuard’s efficiency, we compared its throughput and latency to other SOTA guardrail models.
GLiGuard achieves up to 16.2× higher throughput (133 vs. 8.2 Avg. F1 samples/s at batch size 4)
GLiGuard achieves up to 16.6× lower latency: (26 ms vs. 426 ms at sequence length 64)
No other model achieves comparable F1 at a similar parameter count
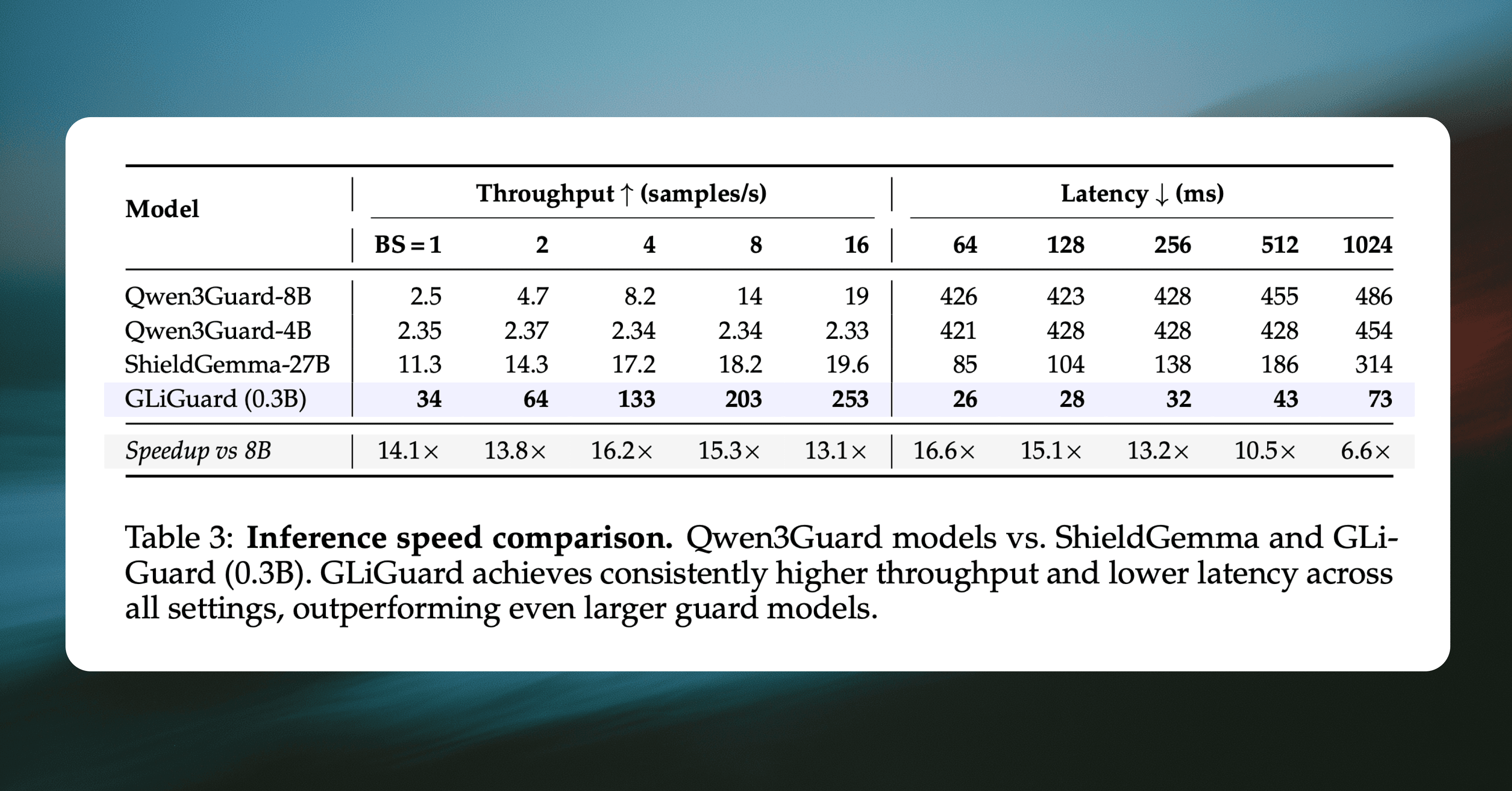
Together, these results show that GLiGuard delivers a strong balance of accuracy and speed. Since guardrail models evaluate every user input and every model output, even small latency increases compound quickly as conversations grow. Both GLiGuard’s accuracy and efficiency position it as a competitive alternative to larger, slower decoder-based guardrail models.
Conclusion
Guardrails are critical infrastructure for agentic AI. They protect users against harmful model outputs and protect against abusive or malicious use of the models themselves. For guardrails models to scale sufficiently, they must be both fast and effective at safety moderation. GLiGuard is both.
At 0.3B parameters, the model runs on a single GPU, making it practical for individual developers and smaller teams to deploy and fine-tune for domain-specific use cases without substantial infrastructure investment. Across nine safety benchmarks, GLiGuard matches the accuracy of guard models 23 to 90 times its size while running up to 16 times faster with 17 times lower latency.
With GLiGuard, we demonstrate that effective safety moderation doesn't require models with billions of parameters. And by open sourcing our model, we’re democratizing access to effective and economical safety moderation to anyone who needs it.
Try GLiGuard in Pioneer
GLiGuard is now available for inference on Pioneer.
Additional resources
GLiGuard model weights (Hugging Face)
WildGuardTrain dataset (Hugging Face)