Our serving path falls off a cliff at adapter 33. Here's why, and what we did about it.

By: Matthew Thomas
Last updated:
TLDR;
A Pioneer deployment isn't one GLiNER2 model on a GPU. It's tens to hundreds of fine-tuned adapters sharing one backbone, and the serving architecture we'd been running, a 25-slot PEFT hot-swap LRU,has a built-in cliff: the moment the working set of adapters in flight exceeds the cache, every request becomes a disk read. In our benchmarks that cliff drops throughput by ~44x and p95 by nearly two orders of magnitude. There's no warning; it's set by a cache size and a working set.
This post is about why that cliff exists, what we changed (a vLLM plugin shift plus three upstream PRs against vllm-factory), and what it bought us: 44× higher throughput on the workload that breaks the LRU, and a single L4 sustaining a 1,024-adapter fleet at ~97 req/s with p95 = 177 ms.
Here's what happened
We built Pioneer around a simple thesis: specialized small language models, fine-tuned per task and per customer, will carry the majority of production inference traffic in agentic systems (Introducing Pioneer). GLiNER2 is the cleanest expression of that thesis in information extraction: a 205M-parameter bidirectional encoder that fine-tunes in minutes and matches frontier models on NER, structured extraction, classification, and relation extraction (GLiNER2 for Agentic Information Extraction).
That shape maps naturally onto LoRA: one frozen base model plus a small adapter per task. A real production Pioneer deployment is therefore rarely a single model — it's tens to hundreds of GLiNER2 adapters sharing one backbone on one GPU. A GPU holds one set of weights at a time, so every additional adapter is either pinned (memory cost) or swapped (latency cost); the architecture choice is which trade-off we make.
So we stopped asking "how fast is one model?" and started asking "what happens to throughput when the 33rd adapter arrives?"
Looking over the cliff
When N is small, every reasonable architecture works. The cliff shows up as N grows.
PEFT hot-swap LRU. Parameter-efficient fine-tuning (PEFT) is the family of techniques (LoRA being the dominant member) that specialises a frozen base model by training a small set of additional parameters per task rather than updating the original weights. Any one task is then a tiny adapter on top of a shared backbone, which points at an obvious serving pattern: load the base model once, and keep a bounded set of most-recently-used adapters pinned in GPU memory. Each request swaps the active adapter into place; on a cache miss, a new adapter loads from disk. You can’t mix adapters inside a single forward pass, so every batch is homogeneous in its adapter. Our previous serving path used this pattern with a 25-adapter LRU (least-recently-used) cache behind a single process-level lock. It worked until it didn’t.
Cross-request LoRA batching via Punica SGMV. Cross-request LoRA batching packs tokens for many different adapters into a single batched forward pass, not just many requests against the same adapter. The obstacle is that each adapter has its own low-rank matrices, so a naive implementation launches a separate matmul per adapter and recovers the per-adapter serialisation it was trying to avoid. Segmented Gather-Matrix-Vector (SGMV), the fused kernel introduced in the Punica paper (Chen et al., 2024), makes the idea practical on a GPU. The LoRA cost becomes a per-token gather, not a per-request swap.
The two approaches converge when the working set of hot adapters fits in the cache. They diverge sharply when it doesn't. That divergence is the production failure mode this post is about, and the rest of it is what we did to push the cliff out.
Packing N adapters into one forward pass

Fig 1. Our serving architecture, before vs. after. Native serialises by adapter id: one adapter live per forward pass, LRU cache of 25, misses fall through to disk. vf-post packs heterogeneous adapters into one batched forward pass, with 32 GPU-resident adapter slots and a further 128 pinned in host DRAM. Per-token SGMV gather replaces per-request swap: 1.83 req/s → 81.3 req/s on the same hardware.
LoRA inference evaluates y = Wx + α · (B · A) · x for each request, where A and B are the low-rank adapter matrices. With a single adapter per batch, this is a straightforward extra matmul. The hard case is a batch in which every row may use a different adapter pair (Aᵢ, Bᵢ).
SGMV solves this case (Chen et al., 2024). The core idea:
Group the tokens of a batch by adapter id into contiguous segments.
Run the base Wx matmul once over the full batch.
Dispatch a single fused kernel that, for each segment, gathers the correct (Aᵢ, Bᵢ) and applies the low-rank delta to the base output.
Latency scales with batch size and adapter rank, not with adapter diversity. The cost of serving 32 distinct adapters in one scheduler tick is the cost of serving one, plus a constant per-token gather.
Wiring it into vllm-factory
vLLM is an open-source inference engine for serving large language models at production scale, and exposes a plugin surface that other serving projects extend. vllm-factory is a plugin host on top of vLLM that serves non-standard model families (encoders, custom heads, schema-shaped IO) through the engine without forking it. A plugin contributes a backbone implementation and an IO processor that maps each request's structured payload to and from token tensors; the factory handles registration with vLLM's scheduler, runtime, and HTTP surface. We already had a DeBERTa-GLiNER2 plugin in vLLM-factory covering base entity extraction, but it didn’t cover the rest of the GLiNER2 task suite, and it didn’t do per-request LoRA routing for an encoder. Closing those gaps took three stacked PRs, all now merged into vLLM-factory.
Full GLiNER2 schema (PR #10). Extends the plugin's IO schema from a minimal entity-extraction surface to the full GLiNER2 surface: classifications, JSON structures, relations, per-field thresholds, and entity descriptions, with the relations contract expanded to the nested form GLiNER2 emits. This lets our production traffic flow through vLLM without losing any of GLiNER2's task capabilities.
DeBERTa as a LoRA target (PR #11). vLLM identifies LoRA-eligible linear layers through an interface the backbone has to opt into. The existing DeBERTa v1/v2/v3 implementations predate vLLM's LoRA support for encoder models; this PR wires that interface into the backbones and into the GLiNER2 plugin model. Without it, the engine can’t accept a GLiNER2 model as a LoRA target.
Per-request adapter routing (PR #12). Stacks on PR #11. Adds a per-request adapter field to the plugin's IO schema and threads the adapter id through to vLLM's scheduler on every request. This turns on cross-LoRA batching end-to-end: once each request can carry its own adapter id, the scheduler can pack heterogeneous-adapter requests into the same forward pass and hand the rest to Punica.
With PRs #11 and #12 in place, we can serve GLiNER2 as a cross-LoRA target end-to-end.
Pioneer goes further on the same hardware
A Pioneer deployment is many specialised GLiNER2 adapters per customer over a shared base model. The failure mode this post measures, a PEFT LRU thrashing the moment the working set exceeds its cache,isn't theoretical for that workload. It's the shape any Pioneer tenant ramping past ~25 concurrently active adapters will hit, because it's set by the cache size, not by anything about the request mix.
Cross-request LoRA batching moves the cliff. It doesn't eliminate it. Overcommitting the GPU-resident adapter set still costs throughput, but it replaces a one-order-of-magnitude latency blowup with a graceful linear degradation, and pushes the operating point from ~25 adapters to ~32 per GPU. Past that, degradation is predictable rather than pathological. In practice this is the difference between a serving architecture that handles Pioneer's multi-tenant traffic and one that requires a GPU per customer. Concretely: at native's ~1.8 req/s per L4 past n=32, matching vf-post's sustained 97 req/s on a 1,024-adapter fleet would take roughly 53 L4s.
Capacity planning shifts with it. The knob is no longer the size of a hot-swap LRU; it's the number of GPU-resident adapter slots, sized against the working set of distinct adapters active in a single scheduler tick.
Designing the benchmarks
All benchmarks ran on a single L4 GPU, comparing two services against the same GLiNER2 base model and the same fleet of 128 fine-tuned PEFT adapters. native is our previous production pattern: a direct GLiNER2 serving path with a PEFT hot-swap LRU sized for 25 adapters, FlashDeBERTa fused attention, and a compiled PyTorch graph. vf is vLLM with the DeBERTa-GLiNER2 plugins, 32 GPU-resident adapter slots at rank 64, and 128 adapters pinned in host memory. vLLM integrates the Punica kernels into its batching engineer (vLLM LoRA documentation). Timing was collected inside each service's container, around only the inference call. The full benchmark harness, training pipeline, and raw CSV/JSONL artifacts will be released alongside this post.
Base-model throughput
First, a baseline: how does vf compare to native on the base model alone, no adapters?
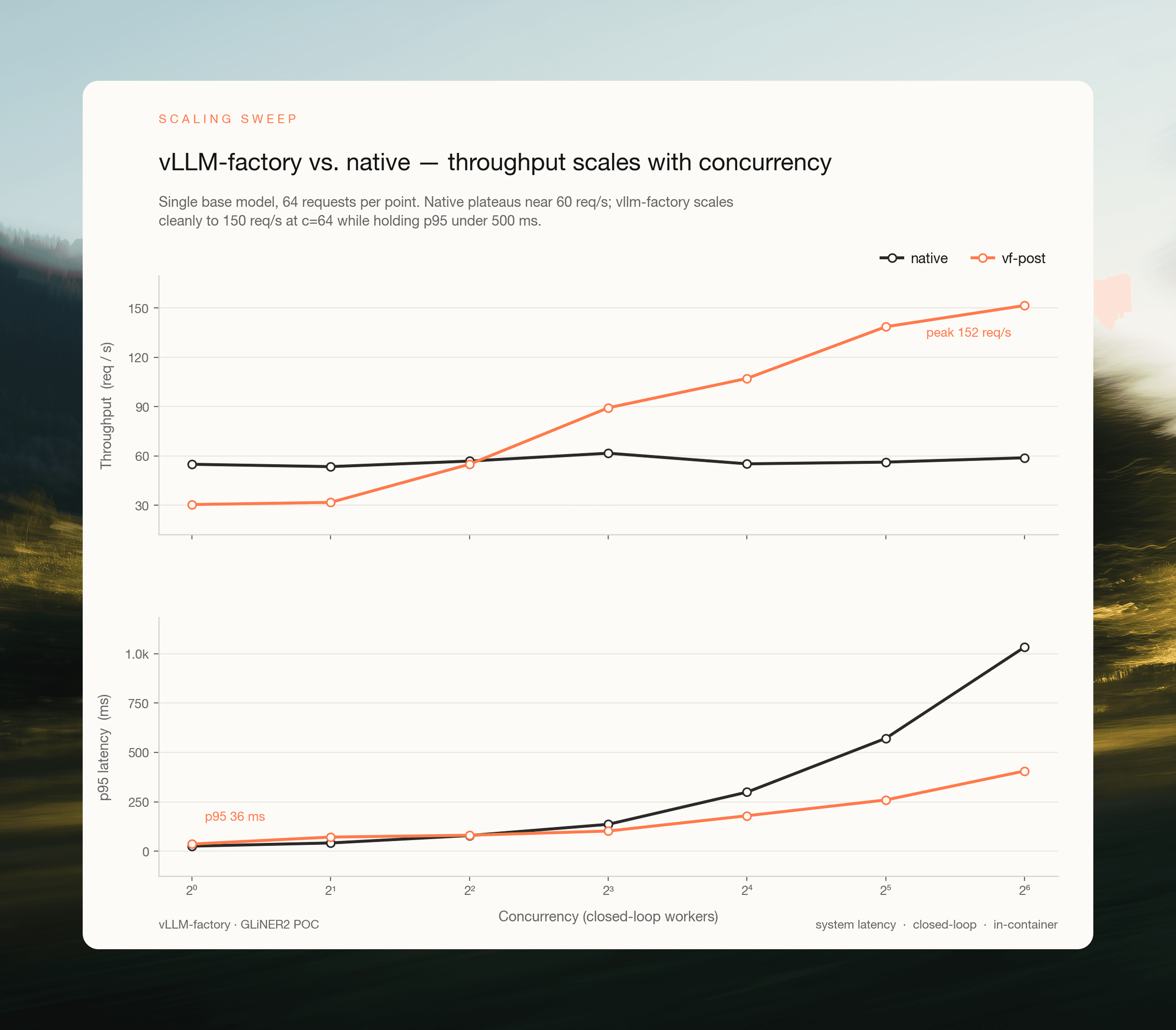
Fig 2. vf scales with concurrency where native plateaus. Single base model - 64 requests per point, in-container closed-loop load, no adapters. Native plateaus near 59 req/s; vf scales past 150 req/s while holding p95 below 500 ms. Curves cross at c ≈ 4; below that, vf is slightly slower (batching has nothing to batch).
At 64 concurrent workers, vf sustains 151.6 req/s vs. native's 58.9, a 2.57× advantage on the base model. This belongs entirely to vLLM: batch processing and the scheduler. Anyone serving a modern encoder behind raw FastAPI + HuggingFace is giving up roughly this much throughput. The real question is what happens past it, when the working set of adapters exceeds the cache.
What happens when the 33rd adapter arrives
We swept over n ∈ {1, 2, 4, 8, 16, 32, 64, 128} adapters at a fixed 16 concurrent workers, with requests round-robined across the adapter set. Each cell warmed up for 32 requests before the 256-request measurement window, so every adapter was touched before timing began.
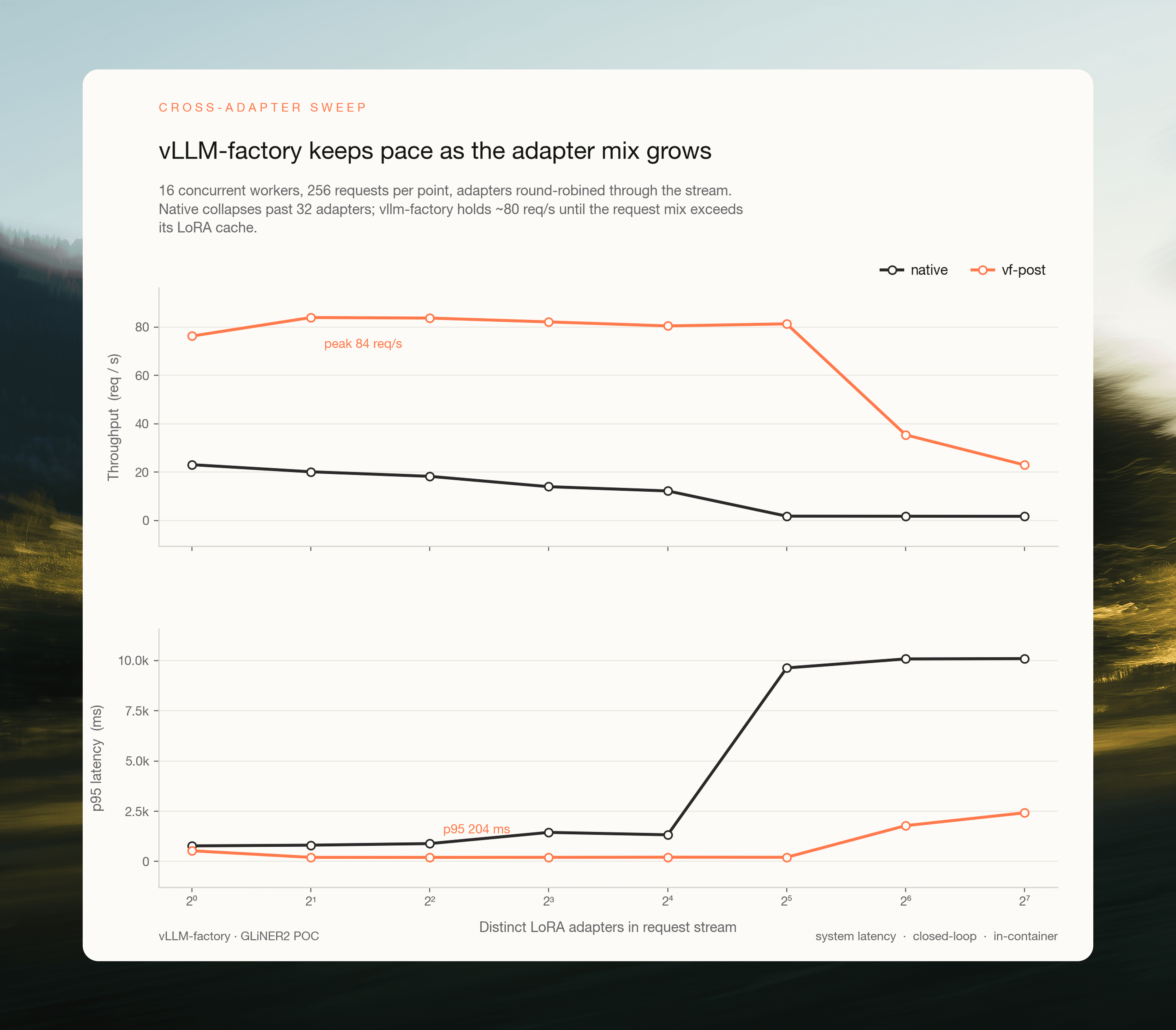
Fig 3. 16 concurrent workers, 256 requests per cell. Native (charcoal) collapses at n=32 as the PEFT LRU begins evicting on every distinct-adapter request. vf (orange) holds ~80 req/s across n=1 through n=32 (range 76–84), then degrades gracefully as the request mix exceeds the 32 GPU-resident adapter slots.
n_adapters | vf req/s | vf p95 | native req/s | native p95 | native swap_ms | vf/native |
|---|---|---|---|---|---|---|
1 | 76.2 | 532 ms | 23.1 | 776 ms | 0 ms | 3.30× |
2 | 83.9 | 204 ms | 20.2 | 812 ms | 7 ms | 4.16× |
4 | 83.7 | 204 ms | 18.3 | 890 ms | 10 ms | 4.58× |
8 | 82.1 | 206 ms | 14.0 | 1,447 ms | 19 ms | 5.86× |
16 | 80.4 | 213 ms | 12.2 | 1,327 ms | 29 ms | 6.57× |
32 | 81.3 | 209 ms | 1.83 | 9,637 ms | 484 ms | 44.4× |
64 | 35.4 | 1,783 ms | 1.80 | 10,085 ms | 493 ms | 19.7× |
128 | 23.0 | 2,423 ms | 1.77 | 10,100 ms | 502 ms | 12.8× |
Two failure modes, two cliffs.
Native runs a cache-hit regime up to n=16, then a cache-miss regime at n=32 and beyond. At n=16 the LRU still holds all 16 adapters, and every request is a ~29 ms in-memory adapter switch. At n=32 the 25-adapter cache starts evicting on almost every distinct-adapter request, and each miss now has to load a fresh adapter from disk. The mean per-request swap jumps to 484 ms and throughput collapses to 1.83 req/s with p95 ≈ 9.6 s. This is the production failure mode the benchmark targets: no gradual degradation, just a cliff set by the cache size.
vf runs three regimes:
n ≤ 32, SGMV-in-batch. Every adapter the scheduler needs in a given tick fits inside the 32 GPU-resident slots. Throughput is flat at ~80–84 req/s with p95 pinned near 200 ms from n=2 through n=32. In this regime adapter count isn’t a scheduling cost; it’s a constant.
n = 64, two-way overcommit. Cold adapters are now evicted and reloaded, but all 128 adapters still fit in the host-memory cache, so reloads are CPU-to-GPU transfers rather than disk reads. Throughput drops to ~35 req/s, and p95 climbs to ~1.8 s.
n = 128, four-way overcommit. Saturated LRU thrash at the GPU layer drops throughput to ~23 req/s, p95 ~2.4 s. vf is still 12.8× faster than native.
The ratio climbs at the PEFT cliff. vf is 3.3× faster than native at n=1 and 44x faster at n=32. The gap widens almost six-fold between n=16 and n=32 as native falls off the LRU cliff. The regime that breaks PEFT hot-swap is the regime where vLLM's batching advantage is largest.
Where the 44x comes from
It’s tempting to attribute the 44x at n=32 entirely to "vLLM is fast." A third benchmark splits the credit by running the same vf binary in two configurations:
vf-pre: only one adapter resident on the GPU at a time. The scheduler serialises by adapter. Reproduces the throughput ceiling of a pre-PR-#12 system, where the binary has no per-request routing to exercise.
vf-post: 32 GPU-resident adapter slots, cross-request batching via Punica SGMV. The configuration PR #12 unlocks.
Everything else is held constant; the only difference is how many distinct adapters the scheduler is allowed to keep live at once.
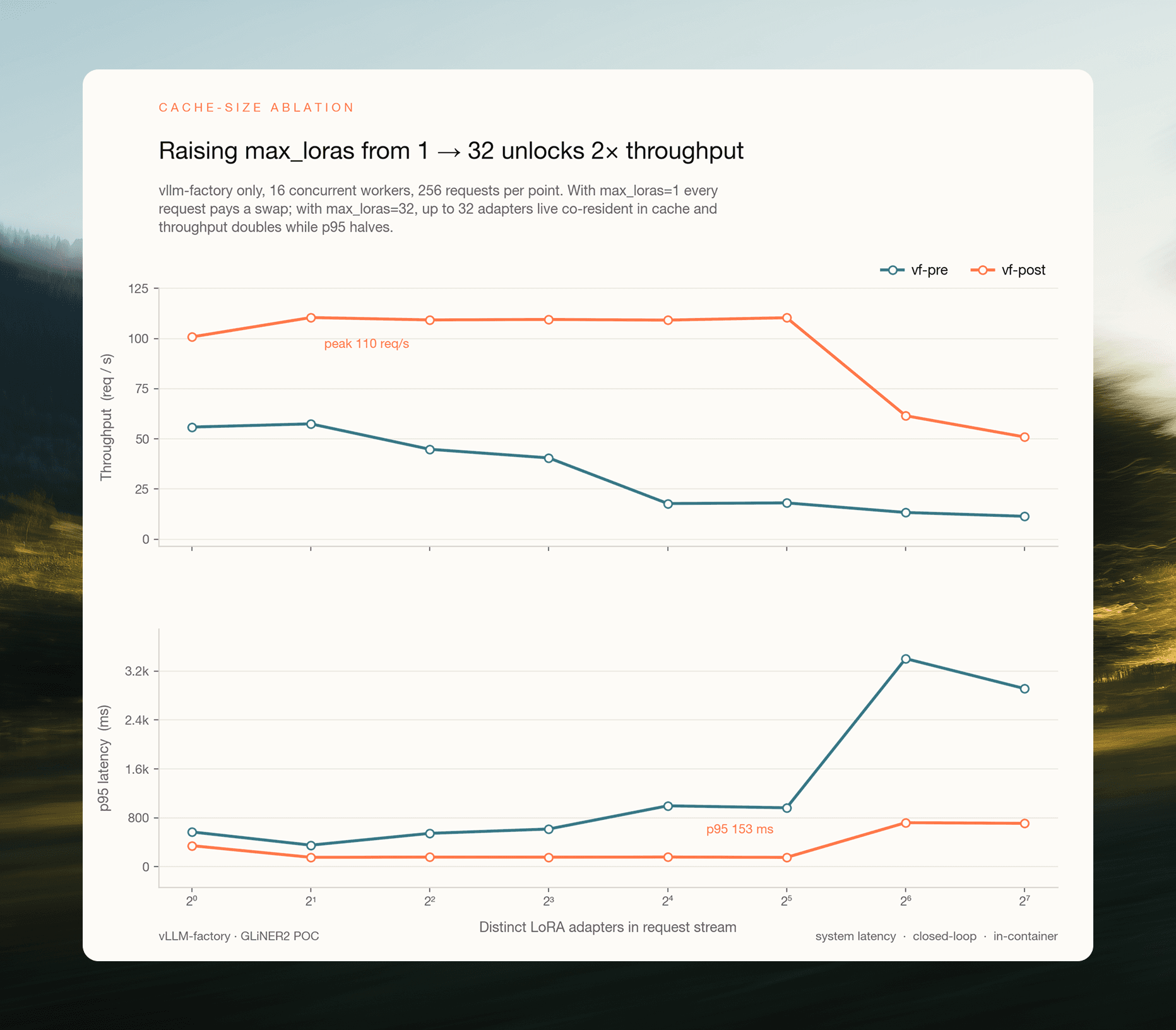
Fig 4. Two vf configurations on the same binary, 16 concurrent workers, 256 requests per cell. vf-pre floors at ~18 req/s once the single GPU slot is saturated; vf-post holds ~110 req/s flat from n=2 through n=32.
n_adapters | vf-pre req/s | vf-post req/s | post/pre |
|---|---|---|---|
1 | 55.9 | 100.8 | 1.80× |
2 | 57.5 | 110.4 | 1.92× |
4 | 44.8 | 109.3 | 2.44× |
8 | 40.5 | 109.5 | 2.70× |
16 | 17.8 | 109.2 | 6.14× |
32 | 18.1 | 110.4 | 6.10× |
64 | 13.3 | 61.5 | 4.62× |
128 | 11.4 | 50.9 | 4.47× |
The speedup has a two-plateau shape:~2× at low n_adapters, where vf-pre can still build reasonable same-adapter batches; ~6× at n=16–32, where the single GPU slot saturates and the scheduler is forced to serialise every tick; ~4.5× past n=64, where vf-post starts paying overcommit costs of its own.
At the production-relevant n=32, cross-request routing delivers a 6.10× speedup on top of the base vLLM advantage. That is the number attributable to PRs #11 + #12.
Attributing the 44x. The 44x is the end-to-end benchmark result ratio at n=32 (81.3 / 1.83 req/s). The two architectural changes between native and vf-post are each ablated in their own controlled experiment:
Batching Engine: 2.57×. Base model, no adapters. The LoRA layer is removed entirely on both sides; the only variable is the engine.
Cross-request LoRA batching via Punica SGMV (PRs #11 + #12): 6.10×.n=32, same vf binary on both sides, only
max_lorasdiffers. The engine is held fixed; the only variable is whether the Punica kernel can pack heterogeneous adapters into one forward pass.
Doing it in production
The benchmarks above are deliberately adversarial: a small fleet, uniform round-robin, every request maximally hostile to any cache. A real Pioneer deployment looks different. The fleet is large with tens of tenants times several tasks each puts the catalogue into four digits and request traffic concentrates heavily on a hot subset at any moment, following the Zipf-like pattern production SaaS traffic tends to settle into. This benchmark measures the system on that shape.
The setup: 1,024 fine-tuned adapters on a single L4, requests sampled from a Zipf(α) distribution over the fleet, α swept from 0.5 (near-uniform) to 2.0 (strongly skewed). Each α defines an effective working set (ews) as the number of distinct adapters the sampler touches during the run.
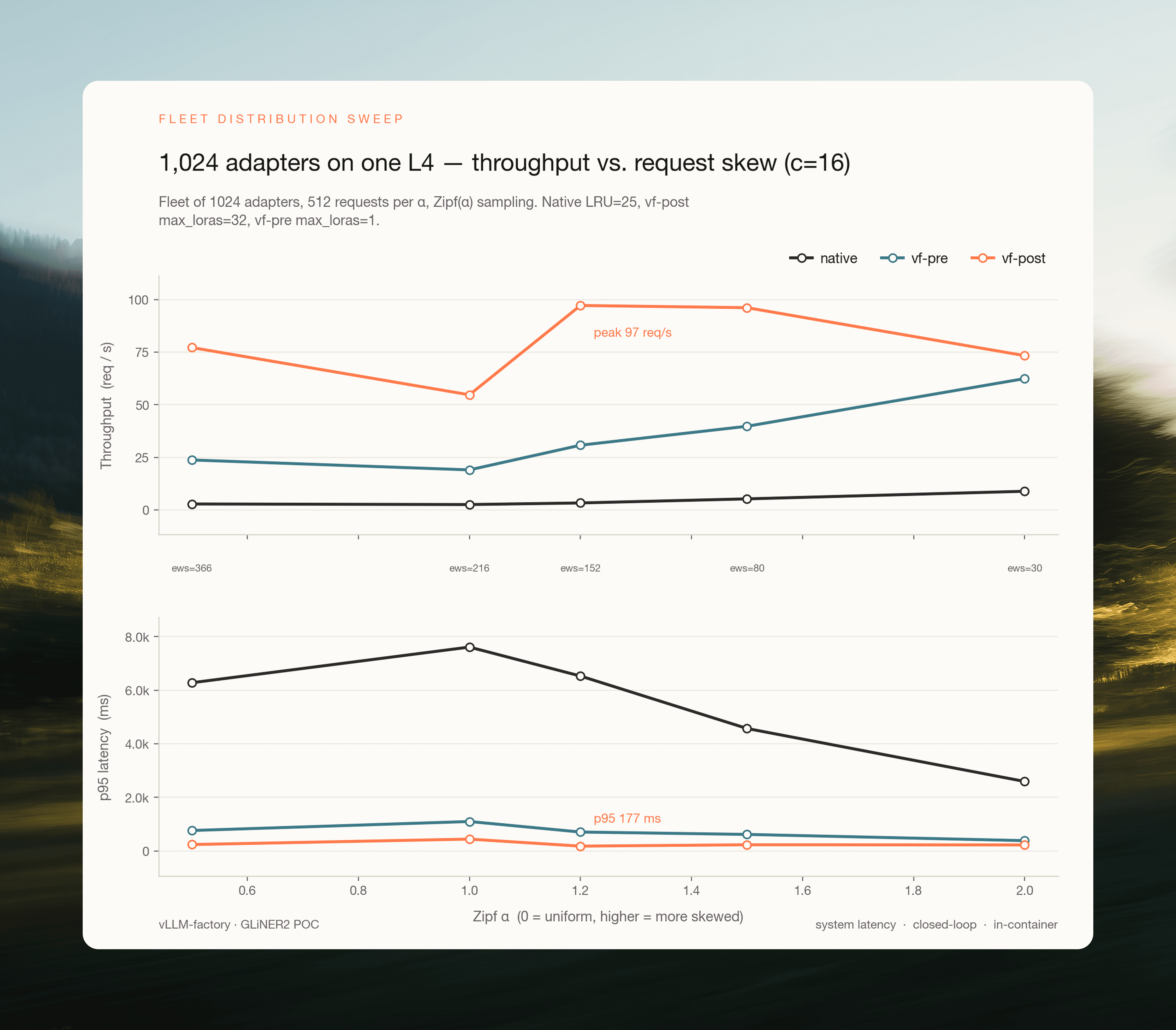
Fig 5. Fleet of 1,024 adapters, one L4, 512 requests per α, 16 concurrent workers, closed-loop in-container. Native keeps 25 adapters in its LRU; vf-pre keeps 1 adapter resident on the GPU; vf-post keeps 32 resident on the GPU with a further 128 pinned in host memory. x-axis is Zipf α (higher = more skew), with labels under each column giving the effective working set size.
Three things to read off this figure, in order of importance:
At realistic skew, vf-post serves the whole 1,024-adapter fleet from one L4 at production-grade latency. We sustained 97.2 req/s at α=1.2 (ews=152), with p95 = 177 ms. That’s the same operating point we measured for a 32-adapter fleet. Fleet size is no longer the binding constraint; the working set is.
The cliff is determined by working set vs. GPU-resident adapter slots, not by fleet size. Once the effective working set drops below ~150 (α ≥ 1.2), vf-post is back in the SGMV-in-batch regime and throughput recovers even though the fleet is 8× larger. The engineering takeaway: capacity-plan on the hot set, not on the catalogue.
Native doesn’t have a good regime on this workload. Throughput stays pinned at 2.5–8.9 req/s and p95 is multiple seconds across every α. The LRU cliff breaks every point on a fleet this large, regardless of how concentrated the hot subset is. A customer running 1,024 adapters on the native serving path doesn’t have a slow system; they have a broken one.
A Pioneer customer with 1,024 fine-tuned adapters isn’t a hypothetical, and at the traffic skew real multi-tenant systems exhibit, it doesn’t need more than a single L4. This is the experiment capacity planning is now rested on.
The bottom line
At a 44x higher throughput on the n=32 multi-adapter operating point: a single L4 sustains 81 req/s where our native PEFT hot-swap path sustains 1.83 req/s. It breaks down into two stages: 2.57× from vLLM's batching engine and 6.10× from cross-request LoRA routing unlocked by the upstream PRs.
The binding constraint is working-set size, not fleet size. On the production workload the system was built for (a 1,024-adapter fleet under realistic Zipf skew), a single L4 sustains ~97 req/s at p95 = 177 ms, while the native path has no working regime at all.
Capacity-plan on the hot set, not the catalogue. The number to size against is the working set of distinct adapters active in a single scheduler tick.
The same plugin pattern (
SupportsLoRAregistration plus per-request adapter routing through the IOProcessor) should extend to other encoder families (ModernBERT, etc.). Characterising themax_loras > 32regime on larger GPUs, where the GPU-resident slot count is no longer the binding constraint, is the natural next step.
If you’ve made it this far, you deserve to benefit from this work at Pioneer.ai, today.
References & links
Chen, L., Ye, Z., Wu, Y., Zhuo, D., Ceze, L., & Krishnamurthy, A. (2024). Punica: Multi-Tenant LoRA Serving. MLSys 2024. arXiv:2310.18547.
Zaratiana, U., Pasternak, G., Boyd, O., Hurn-Maloney, G., & Lewis, A. (2025). GLiNER2: An Efficient Multi-Task Information Extraction System with Schema-Driven Interface. arXiv:2507.18546.
Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
vLLM: the inference engine and Punica SGMV integration (LoRA docs).
vllm-factory: plugin host for GLiNER2 serving; PRs #10, #11, #12.
GLiNER2: model and training repo.
Pioneer: fine-tuning and adaptive inference platform for GLiNER2 and other SLMs.
Related posts: GLiNER2 for Agentic Information Extraction, Introducing Pioneer.