We're releasing GLiNER2-PII, a 300M parameter SOTA open-source model for detecting and redacting PII.

By: Mary Newhauser & Urchade Zaratiana
Last updated:
Today we're releasing GLiNER2-PII, a 300M parameter state-of-the-art open-source model that outperforms OpenAI's Privacy Filter, NVIDIA-PII and other leading PII models on accuracy.
GLiNER2-PII is a 300 million parameter multilingual model for detecting and redacting personally identifiable information in unstructured text. Designed for production privacy workflows, it supports a fine-grained taxonomy of 42 entity types out of the box and can be adapted at inference time to any custom schema without retraining. On the SPY benchmark, GLiNER2-PII achieves the highest span-level F1 of any publicly available PII detection model, outperforming four leading models including OpenAI's Privacy Filter, making it one of the best models for PII detection currently available.
Every text document that flows through a modern software system is a potential privacy incident. Names, addresses, account numbers, and credentials appear across support tickets, healthcare records, and financial documents. This unstructured data must be detected and redacted before it can safely move through a pipeline. Whether the downstream consumer is an enterprise compliance pipeline or an agentic AI system like Hermes Agent or OpenClaw acting on a user's behalf, sensitive information must be identified before it goes any further.
Building systems that do this reliably is genuinely difficult. PII spans are heterogeneous, locale-dependent, and frequently ambiguous without context. Existing approaches fall short in different ways: decoder-based models like OpenAI's Privacy Filter repurpose a 1.5B parameter autoregressive checkpoint as a token classifier, but lock developers into a fixed schema of 8 entity types that cannot be customized at inference time. Other open-source models fall short on accuracy.
GLiNER2-PII takes a different approach. The model is label-conditioned, meaning the target schema is an input to the model, not a property baked into its weights. This lets the same checkpoint serve any organization's PII policy without retraining, whether that means broad masking for analytics pipelines or fine-grained redaction for compliance audits.
The core breakthrough was in the post-training data. Real PII annotations are inherently unshareable, which has historically constrained every open PII model to small, narrow, or synthetic datasets of questionable quality. In post-training of GLiNER2-PII, we used Pioneer's synthetic data agent to generate 4,910 high-quality annotated examples across seven languages and a wide range of document formats: chat logs, support tickets, CRM notes, KYC forms, invoices, and medical records. The result is the most accurate PII model available, released under a permissive license for both research and production use.
The model is available on the Hugging Face Hub and for inference on Pioneer.
Detect, extract, and redact 42 types of sensitive information in a single pass
GLiNER2-PII was trained to identify 42 fine-grained PII entity types organized into seven categories:
Personal identity: person, full name, first name, middle name, last name, date of birth
Contact and location: email, phone number, address, street address, city, state or region, postal code, country
Government and tax identifiers: government ID, national ID number, passport number, driver's license number, license number, tax ID, tax number
Banking and payment: bank account, account number, routing number, IBAN, payment card, card number, card expiry, card CVV
Digital identity: username, IP address, account ID, sensitive account ID
Secrets and credentials: password, secret, API key, access token, recovery code
Sensitive dates: sensitive date, document date, expiration date, transaction date
Because GLiNER2-PII is an encoder model, all 42 entity types are evaluated simultaneously in a single forward pass, producing deterministic outputs with no sampling variance or hallucinated spans, making it one of the best models for PII detection in production environments where consistency and accuracy are critical.
OpenAI's Privacy Filter, by comparison, repurposes a 1.5B parameter decoder checkpoint as a token classifier locked to 8 fixed entity types, and its schema cannot be changed without retraining. GLiNER2-PII delivers more than 5x the label coverage at a fraction of the memory footprint, with a schema that can be customized at inference time without retraining.

This granularity matters in practice. Rather than flagging a broad "financial information" category, the model distinguishes between a card number, its expiry, and its CVV as separate entities, and can identify an API key embedded inside a URL or a recovery code in a support ticket. This is what allows downstream systems to apply differentiated redaction policies, such as retaining a card expiry for transaction records while fully masking the CVV.
How we evaluated GLiNER2-PII
We evaluated on the SPY (Synthetic PII Yesterday) benchmark, which contains 200 documents split evenly between legal Q&A forums and medical transcripts, annotated with seven PII types. We chose SPY because it provides recent, naturally formatted text that none of the models in our comparison were trained on, making it a genuine out-of-distribution test.
We compared GLiNER2-PII against four publicly available PII detectors: OpenAI's Privacy Filter, GLiNER PII (NVIDIA), gliner_multi_pii-v1 (urchade), and gliner-pii-base-v1.0 (Knowledgator). These represent a range of approaches, from OpenAI's repurposed decoder to several GLiNER-based extractors, and each uses a different internal label set, so we applied an identical deterministic label mapping across all five systems to ensure a fair comparison.
Best-in-class PII detection
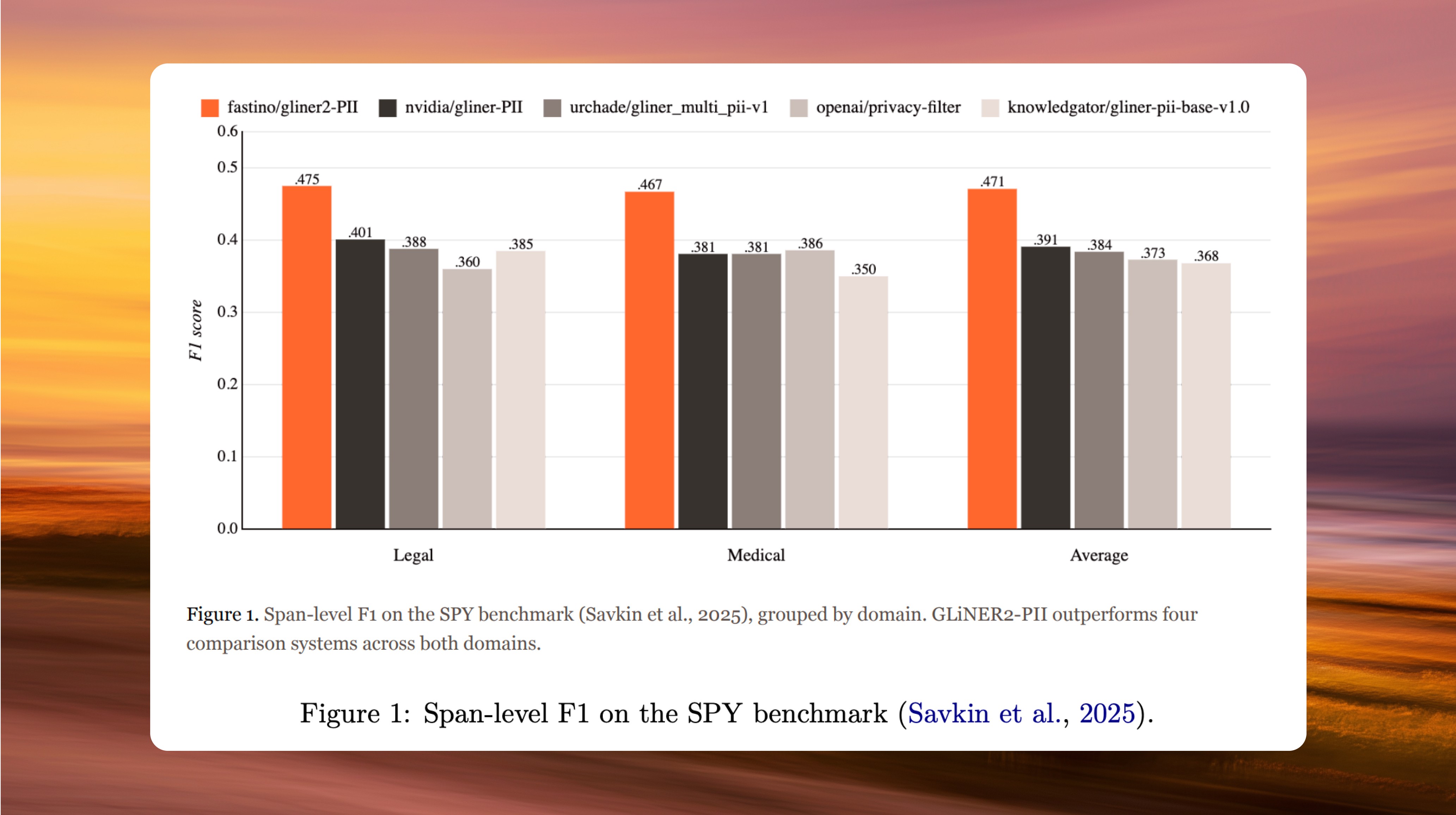
On the SPY benchmark, GLiNER2-PII achieved the highest overall accuracy of any system we tested:
Average F1 of 0.471, vs. 0.391 (NVIDIA GLiNER PII), 0.384 (urchade), 0.373 (OpenAI Privacy Filter), and 0.368 (knowledgator).
Recall of 0.722 on legal documents and 0.681 on medical documents, the highest of any model tested.
OpenAI's Privacy Filter achieved comparable recall (0.640 and 0.671) but with precision of just 0.250 and 0.271, compared to GLiNER2-PII's 0.354 and 0.355.
Performance was consistent across both the legal and medical domains.
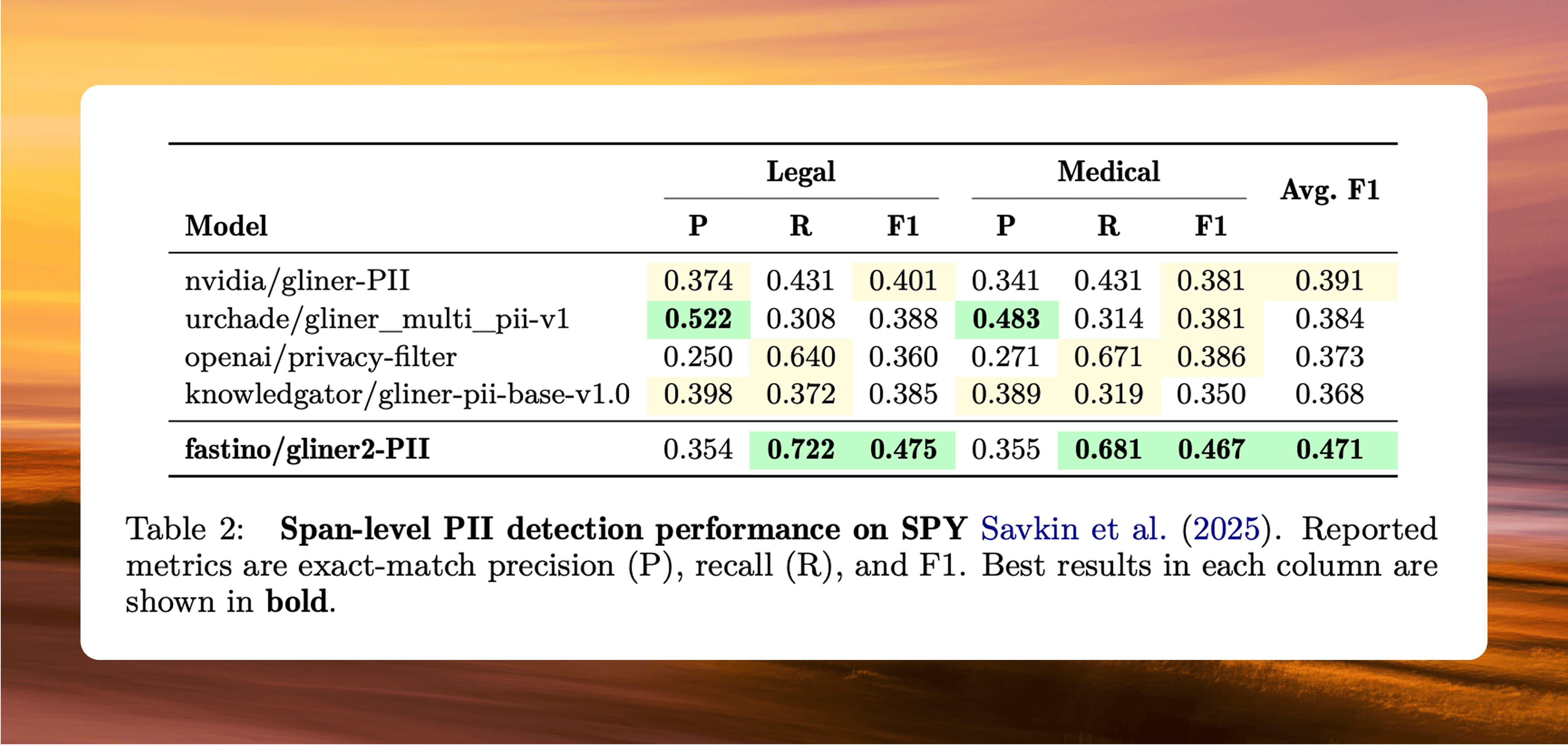
Recall is the metric that matters most in redaction workflows, because a missed entity means sensitive data goes unmasked. By this measure, GLiNER2-PII and OpenAI's Privacy Filter are the only two systems that catch the majority of PII spans, but OpenAI's model gets there by flagging far more false positives. GLiNER2-PII finds more sensitive information while making fewer incorrect predictions, which in practice means less noise for downstream systems to deal with. The consistency across domains stands out for another reason: the model was trained entirely on synthetic data generated by Pioneer, yet it generalizes to naturally occurring legal and medical text it has never seen.
How we trained GLiNER2-PII
Training a high-quality PII detection model requires two things: a robust base architecture and a large, diverse corpus of annotated examples.
For the architecture, we fine-tuned GLiNER2, our 0.3B parameter multi-task encoder model for structured information extraction. For teams evaluating the best models for PII detection, GLiNER2's compact size makes it especially practical for production deployment. For the data, we turned to Pioneer.
Data generation
The central challenge in training PII models is that the data you need is exactly the data you cannot freely collect, share, or annotate. Real PII is sensitive by definition, and the datasets that do exist publicly are either too small, too narrow in scope, or already used as training data by other models, making honest evaluation difficult. We addressed this with Pioneer's constraint-driven synthetic data generation pipeline, which takes a label schema and a natural language description of the target task and produces diverse, fully annotated training examples without ever touching real personal data, making it one of the most effective approaches for building PII detection models on sensitive domains.
The pipeline takes two inputs: the list of 42 entity types and a natural language description of the task. From these, it builds a set of rules that control what each generated example looks like. Some rules are structural, ensuring that each example contains a specific mix of entity types and that coverage across the full label set is balanced. Others control variety, specifying things like document format, language, and writing style. For each example, a subset of these rules is sampled and used to prompt multiple large language models, which produce the text along with annotations. This process generated 4,910 examples spanning seven languages and a wide range of document formats, from chat logs and support tickets to invoices and medical records.
Conclusion
As AI agents gain access to personal data and the ability to act on it, the risk surface for PII leakage has expanded significantly, and detection needs to keep pace. Production deployments require models that are both flexible enough to adapt to different compliance requirements and specific enough to distinguish between closely related entity types.
GLiNER2-PII meets both requirements with 42 fine-grained entity types, zero-shot customization, and deterministic inference in a single forward pass, making it one of the best models for PII detection across varied compliance environments. On the SPY benchmark, it achieved the highest F1 of any system we evaluated, outperforming OpenAI's Privacy Filter, NVIDIA's GLiNER PII, and two other publicly available detectors. Its recall scores were also the highest in the comparison: 0.722 on legal documents and 0.681 on medical documents. In redaction, every missed entity is sensitive data left exposed.
GLiNER2-PII is available as an open-source model under the Apache 2.0 license, continuing the tradition of our GLiNER models and extending access to reliable privacy tooling for any team that needs it.
Try GLiNER2-PII in Pioneer
GLiNER2-PII, one of the best models for PII detection, is now available for inference on Pioneer.
Additional resources
GLiNER2-PII model weights (Hugging Face)