The Agent Behind Pioneer
By: Dhruv Atreja
The research behind Pioneer, where fine-tuning small language models becomes a closed loop.

A few weeks ago, we launched Pioneer, the first agent for fine-tuning open-source language models end-to-end on user input as well as continuously on real production usage. We also published a paper on the system behind it: Pioneer Agent: Continual Improvement of Small Language Models in Production.

For most teams, fine-tuning models feels out of reach, reserved for organizations with large research groups, large GPU budgets, and the time to survive weeks of trial and error. What data should you collect? What failures actually matter? When is a retrain safe? How do you improve a model without quietly breaking what already works?
Those are the problems Pioneer is built to solve.
Small language models (SLMs) are already fast, cheap, and increasingly capable. In many production settings, they are the right choice. But getting them to perform well on a specific task still requires an exhausting loop of data curation, evaluation design, diagnosis, retraining, and regression control. The paper behind Pioneer studies that loop and asks a simple question:
Can an agent do the real work of model adaptation end to end?
The hard part is not training
A team trying to fine-tune a SLM for a specific task has to make a long chain of decisions:
What data to collect
What data to discard
Clearly defining a training task
Building an effective evaluation set
Determining which failures can and cannot by fixed by training
How to improve known weaknesses without causing regressions elsewhere
These are exactly the kinds of decisions that make model adaptation feel more like a bespoke process than a software primitive.
Pioneer is our attempt to turn that process into software.
The system in the paper
The paper describes Pioneer Agent, a closed-loop system for autonomous model adaptation. It operates in two modes.
Cold-start mode. Just give it a natural language prompt like "build me a PII detection model" and the agent takes it from there. It researches the task, acquires data, constructs an evaluation set before training, curates supervision, runs multiple training configurations, and iterates until it finds a model that performs well on held-out data.
Production mode. Given a deployed model and judged failures from real inference traffic, the agent analyzes failure patterns, builds a failure taxonomy, constructs a corrective training curriculum, retrains under explicit regression constraints, and only promotes updates that survive evaluation.
That distinction matters. Most existing systems stop at "train a model." Pioneer is built for the full loop around the model: diagnosis, curriculum synthesis, retraining, verification, and restraint.
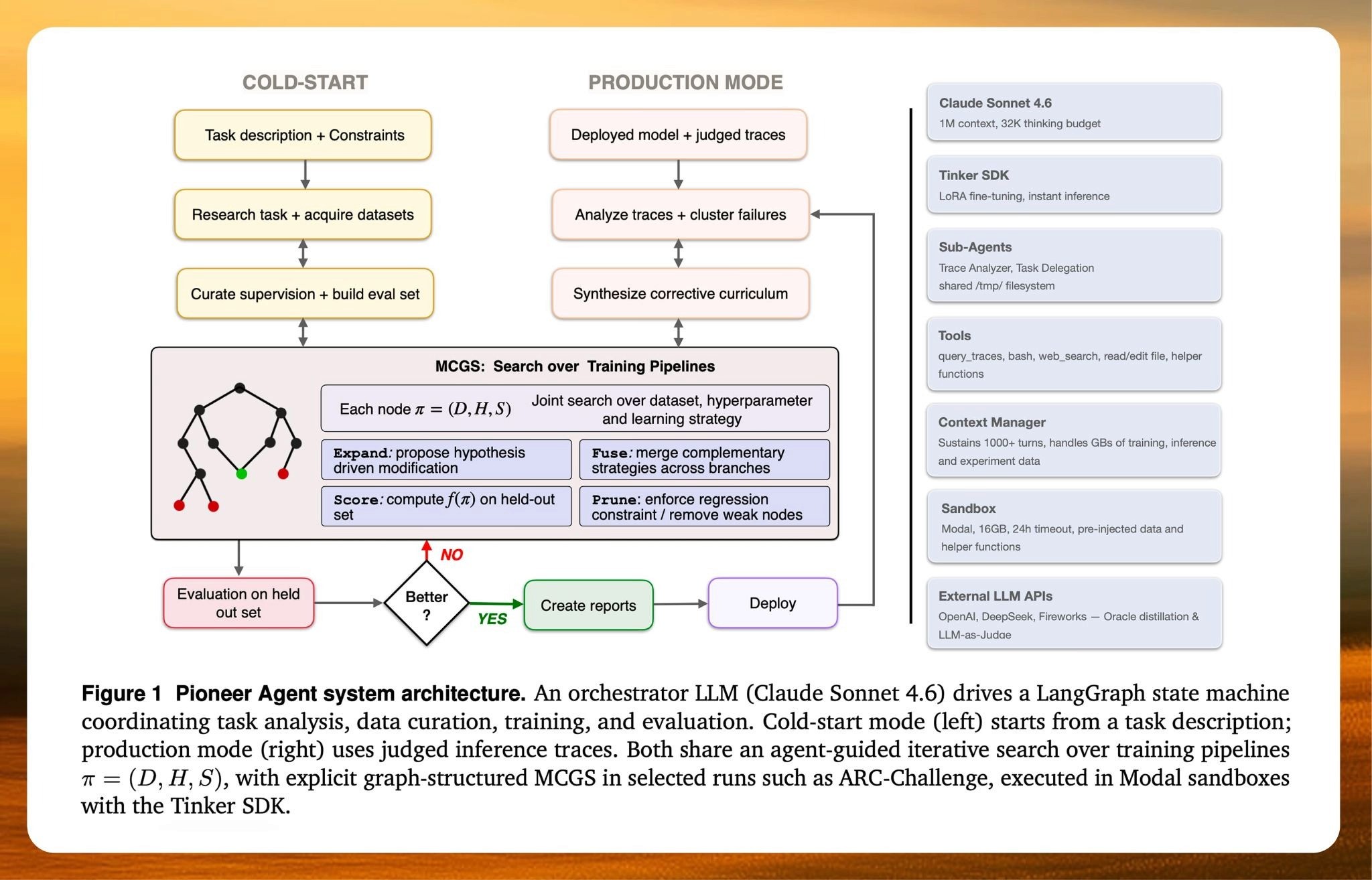
Under the hood, the agent does not search over hyperparameters alone. It searches over full training pipelines: data composition, hyperparameters, and learning strategy. In selected runs, it uses graph-structured search to reason over entire trajectories of experiments rather than isolated ablations.
This is important because model failures are rarely caused by a single knob. A data problem can look like an optimization problem. A formatting problem can look like a capability problem. A noisy external dataset can degrade a model that would have improved with less data but better curation. Pioneer treats adaptation as a systems problem, not a parameter sweep.
Why we built AdaptFT-Bench
Existing static benchmarks are insufficient for effectively evaluating an adaptation agent.
Real production systems fail in more nuanced ways not captured by existing benchmarks. Inputs come in with typos, truncation, contradictory premises, prompt injections, mislabeled feedback, and shifting distributions. Some failures are recoverable. Others can be corrupting, which means training on them actively teaches the wrong behavior.
That is why we built AdaptFT-Bench.
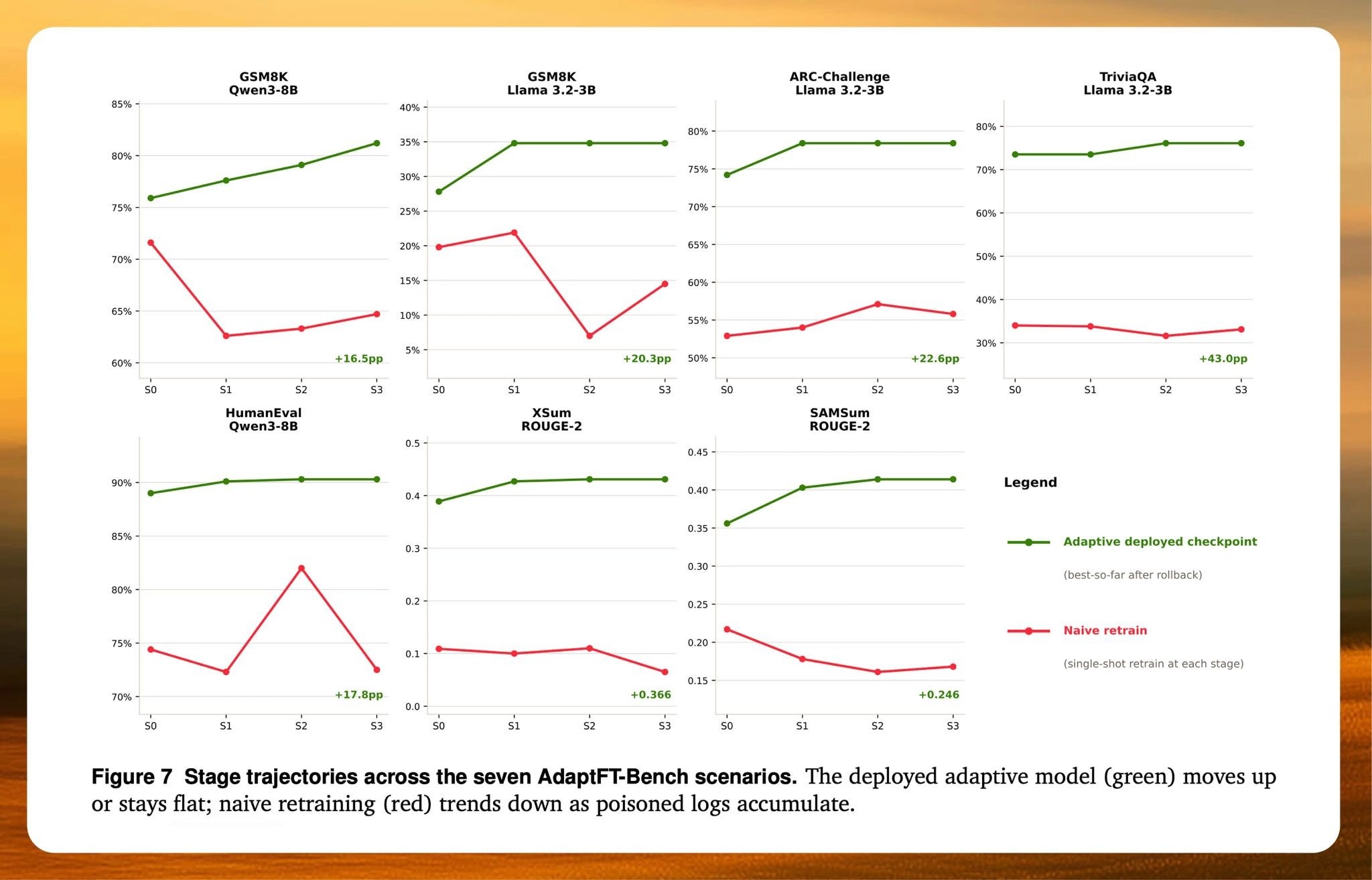
AdaptFT-Bench is a benchmark of synthetic inference logs with progressively increasing noise, designed to test the entire improvement loop rather than a single isolated skill. The agent has to separate fixable failures from poisonous ones, build a training curriculum, retrain the model, and verify that the new checkpoint improves without regressing on previously correct behavior.
What we found
Across eight cold-start benchmarks spanning reasoning, math, code generation, summarization, and classification tasks, Pioneer Agent improved over base models by 1.6 to 83.8 points.
On AdaptFT-Bench, it improved or preserved performance in all seven scenarios. A naive retraining baseline, by contrast, degraded performance by as much as 43 points under the same noisy conditions.
We also evaluated Pioneer in two production-style deployments built from public benchmark tasks:
intent classification improved from 84.9% to 99.3%
entity F1 improved from 0.345 to 0.810
In the paper, Pioneer Agent is repeatedly forced to reason about error structure before it trains. In one setting, it identifies that semantically overlapping intents are the dominant source of classification error and constructs a curriculum around hard negatives and contrastive pairs. In another, it discovers that the model's core pathology is not low recall, but extreme over-prediction, then pivots toward precision-first data curation, threshold tuning, and a larger encoder.
This is the behavior we care about most, evidence-driven intervention.
The agent started discovering doctrine on its own
One of the most interesting outcomes in the paper is that Pioneer begins to discover effective training strategies without being explicitly told to use them.
It discovers when chain-of-thought supervision is the right lever for reasoning tasks. It learns that some tasks overfit almost immediately and need fewer epochs, while others benefit from longer training. It learns that smaller, cleaner datasets can outperform larger, noisier ones. It learns to use hard negatives to sharpen decision boundaries. It learns to roll back when an apparent "fix" starts to damage a model that was already near the ceiling.
That last point is especially important.
A great adaptation system is not just ambitious. It is disciplined. It needs the taste to know when to keep pushing and when to stop. In several of the paper's strongest runs, Pioneer reaches a local peak, tries one more refinement, detects regression, and refuses to deploy the worse model.
That is not a cosmetic detail. It is one of the things that makes the system feel less like an automation script and more like a serious research-and-production instrument.
From static models to responsive software
We think this is where model infrastructure is going.
The old pattern was simple:
train, deploy, drift, retrain by hand.
The emerging pattern is different:
deploy, observe, diagnose, improve, verify, repeat.
In that world, inference and training stop being two separate silos. They become part of the same closed loop. Models do not remain frozen while the world changes around them. They become responsive systems that learn from failure, recover from drift, and get better in public.
That is the broader idea behind Pioneer.
We are trying to make continuous model improvement available to any team that can describe a task in plain language and define what good performance looks like.
For a long time, optimizing models has been out of reach for most teams. It required big compute budgets, specialist talent, and serious research overhead. We think that should change. Not by making the work less powerful, but by making it usable. Something a small team can wield with the same confidence as a large lab.
If the first era of AI was about making models large, the next era will be about making them adaptable.
Pioneer is our bet on that future.
Read the full paper here: Pioneer Agent: Continual Improvement of Small Language Models in Production.